devops-exercises
Kubernetes
What’s your goal?
- I would like to prepare for CKA certification
- See CKA page
- I would like to learn Kubernetes by practicing both theoritcal and practical material
- I would like to learn practical Kubernetes
- Solve exercises
- Kubernetes
- Kubernetes Exercises
- Kubernetes Questions
- Kubernetes 101
- Cluster and Architecture
- Pods
- Labels and Selectors
- Deployments
- Services
- Ingress
- ReplicaSets
- DaemonSet
- StatefulSet
- Storage
- Networking
- Network Policies
- etcd
- Namespaces
- Operators
- Secrets
- Volumes
- Access Control
- Patterns
- CronJob
- Misc
- Gatekeeper
- Policy Testing
- Helm
- Security
- Troubleshooting Scenarios
- Istio
- Controllers
- Scheduler
- Taints
- Resource Limits
- Monitoring
- Kustomize
- Deployment Strategies
- Scenarios
Kubernetes Exercises
Pods
| Name | Topic | Objective & Instructions | Solution | Comments |
|---|---|---|---|---|
| My First Pod | Pods | Exercise | Solution | |
| “Killing” Containers | Pods | Exercise | Solution |
Service
| Name | Topic | Objective & Instructions | Solution | Comments |
|---|---|---|---|---|
| Creating a Service | Service | Exercise | Solution |
ReplicaSet
| Name | Topic | Objective & Instructions | Solution | Comments |
|---|---|---|---|---|
| Creating a ReplicaSet | ReplicaSet | Exercise | Solution | |
| Operating ReplicaSets | ReplicaSet | Exercise | Solution | |
| ReplicaSets Selectors | ReplicaSet | Exercise | Solution |
Labels and Selectors
| Name | Topic | Objective & Instructions | Solution | Comments |
|---|---|---|---|---|
| Labels and Selectors 101 | Labels, Selectors | Exercise | Solution | |
| Node Selectors | Labels, Selectors | Exercise | Solution |
Scheduler
| Name | Topic | Objective & Instructions | Solution | Comments |
|---|---|---|---|---|
| Taints 101 | Taints | Exercise | Solution |
Kustomize
| Name | Topic | Objective & Instructions | Solution | Comments |
|---|---|---|---|---|
| common labels | Kustomize | Exercise | Solution |
Kubernetes Questions
Kubernetes 101
What is Kubernetes? Why organizations are using it?
Kubernetes is an open-source system that provides users with the ability to manage, scale and deploy containerized applications. To understand what Kubernetes is good for, let's look at some examples: * You would like to run a certain application in a container on multiple different locations and sync changes across all of them, no matter where they run * Performing updates and changes across hundreds of containers * Handle cases where the current load requires to scale up (or down)
When or why NOT to use Kubernetes?
- If you manage low level infrastructure or baremetals, Kubernetes is probably not what you need or want - If you are a small team (like less than 20 engineers) running less than a dozen of containers, Kubernetes might be an overkill (even if you need scale, rolling out updates, etc.). You might still enjoy the benefits of using managed Kubernetes, but you definitely want to think about it carefully before making a decision on whether to adopt it.
What are some of Kubernetes features?
- Self-Healing: Kubernetes uses health checks to monitor containers and run certain actions upon failure or other type of events, like restarting the container - Load Balancing: Kubernetes can split and/or balance requests to applications running in the cluster, based on the state of the Pods running the application - Operators: Kubernetes packaged applications that can use the API of the cluster to update its state and trigger actions based on events and application state changes - Automated Rollout: Gradual updates roll out to applications and support in roll back in case anything goes wrong - Scaling: Scaling horizontally (down and up) based on different state parameters and custom defined criteria - Secrets: you have a mechanism for storing user names, passwords and service endpoints in a private way, where not everyone using the cluster are able to view it
What Kubernetes objects are there?
* Pod * Service * ReplicationController * ReplicaSet * DaemonSet * Namespace * ConfigMap ...
What fields are mandatory with any Kubernetes object?
metadata, kind and apiVersion
What is kubectl?
Kubectl is the Kubernetes command line tool that allows you to run commands against Kubernetes clusters. For example, you can use kubectl to deploy applications, inspect and manage cluster resources, and view logs.
What Kubernetes objects do you usually use when deploying applications in Kubernetes?
* Deployment - creates the Pods () and watches them * Service: route traffic to Pods internally * Ingress: route traffic from outside the cluster
Why there is no such command in Kubernetes? kubectl get containers
Becaused container is not a Kubernetes object. The smallest object unit in Kubernetes is a Pod. In a single Pod you can find one or more containers.
What actions or operations you consider as best practices when it comes to Kubernetes?
- Always make sure Kubernetes YAML files are valid. Applying automated checks and pipelines is recommended. - Always specify requests and limits to prevent situation where containers are using the entire cluster memory which may lead to OOM issue - Specify labels to logically group Pods, Deployments, etc. Use labels to identify the type of the application for example, among other things
Cluster and Architecture
What is a Kubernetes Cluster?
Red Hat Definition: "A Kubernetes cluster is a set of node machines for running containerized applications. If you’re running Kubernetes, you’re running a cluster. At a minimum, a cluster contains a worker node and a master node." Read more [here](https://www.redhat.com/en/topics/containers/what-is-a-kubernetes-cluster)
What is a Node?
A node is a virtual or a physical machine that serves as a worker for running the applications.
It's recommended to have at least 3 nodes in a production environment.
What the master node is responsible for?
The master coordinates all the workflows in the cluster: * Scheduling applications * Managing desired state * Rolling out new updates
Describe shortly and in high-level, what happens when you run kubectl get nodes
1. Your user is getting authenticated 2. Request is validated by the kube-apiserver 3. Data is retrieved from etcd
True or False? Every cluster must have 0 or more master nodes and at least 1 worker
False. A Kubernetes cluster consists of at least 1 master and can have 0 workers (although that wouldn't be very useful...)
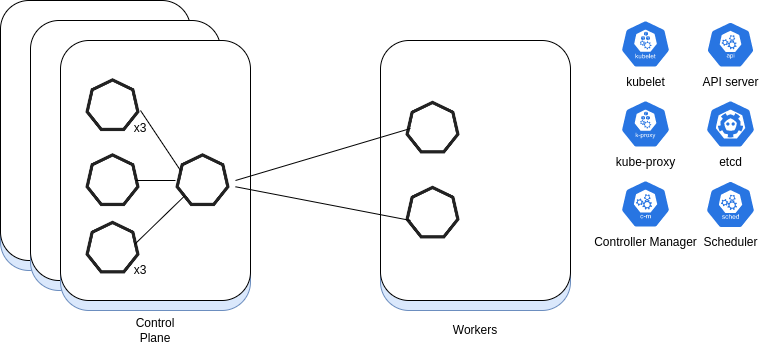
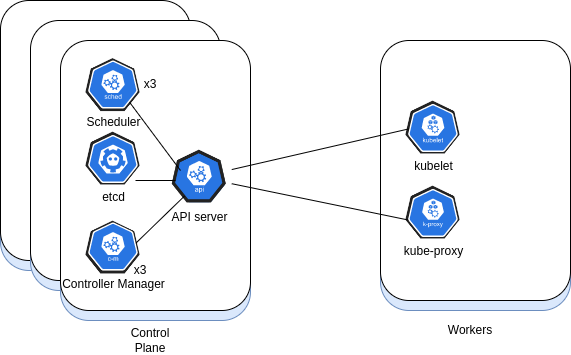
What are the components of the master node (aka control plane)?
* API Server - the Kubernetes API. All cluster components communicate through it * Scheduler - assigns an application with a worker node it can run on * Controller Manager - cluster maintenance (replications, node failures, etc.) * etcd - stores cluster configuration
What are the components of a worker node (aka data plane)?
* Kubelet - an agent responsible for node communication with the master. * Kube-proxy - load balancing traffic between app components * Container runtime - the engine runs the containers (Podman, Docker, ...)
Place the components on the right side of the image in the right place in the drawing
You are managing multiple Kubernetes clusters. How do you quickly change between the clusters using kubectl?
`kubectl config use-context`
How do you prevent high memory usage in your Kubernetes cluster and possibly issues like memory leak and OOM?
Apply requests and limits, especially on third party applications (where the uncertainty is even bigger)
Do you have experience with deploying a Kubernetes cluster? If so, can you describe the process in high-level?
1. Create multiple instances you will use as Kubernetes nodes/workers. Create also an instance to act as the Master. The instances can be provisioned in a cloud or they can be virtual machines on bare metal hosts. 2. Provision a certificate authority that will be used to generate TLS certificates for the different components of a Kubernetes cluster (kubelet, etcd, ...) 1. Generate a certificate and private key for the different components 3. Generate kubeconfigs so the different clients of Kubernetes can locate the API servers and authenticate. 4. Generate encryption key that will be used for encrypting the cluster data 5. Create an etcd cluster
Which command will list all the object types in a cluster?
`kubectl api-resources`
What kubectl get componentstatus does?
Outputs the status of each of the control plane components.
Kubelet
What happens to running pods if if you stop Kubelet on the worker nodes?
When you stop the kubelet service on a worker node, it will no longer be able to communicate with the Kubernetes API server. As a result, the node will be marked as NotReady and the pods running on that node will be marked as Unknown. The Kubernetes control plane will then attempt to reschedule the pods to other available nodes in the cluster.
Nodes Commands
Run a command to view all nodes of the cluster
`kubectl get nodes` Note: You might want to create an alias (`alias k=kubectl`) and get used to `k get no`
Create a list of all nodes in JSON format and store it in a file called "some_nodes.json"
`k get nodes -o json > some_nodes.json`
Check what labels one of your nodes in the cluster has
`k get no minikube --show-labels`
Pods
Explain what is a Pod
A Pod is a group of one or more containers, with shared storage and network resources, and a specification for how to run the containers. Pods are the smallest deployable units of computing that you can create and manage in Kubernetes.
Deploy a pod called "my-pod" using the nginx:alpine image
`kubectl run my-pod --image=nginx:alpine` If you are a Kubernetes beginner you should know that this is not a common way to run Pods. The common way is to run a Deployment which in turn runs Pod(s). In addition, Pods and/or Deployments are usually defined in files rather than executed directly using only the CLI arguments.
What are your thoughts on "Pods are not meant to be created directly"?
Pods are usually indeed not created directly. You'll notice that Pods are usually created as part of another entities such as Deployments or ReplicaSets. If a Pod dies, Kubernetes will not bring it back. This is why it's more useful for example to define ReplicaSets that will make sure that a given number of Pods will always run, even after a certain Pod dies.
How many containers can a pod contain?
A pod can include multiple containers but in most cases it would probably be one container per pod. There are some patterns where it makes to run more than one container like the "side-car" pattern where you might want to perform logging or some other operation that is executed by another container running with your app container in the same Pod.
What use cases exist for running multiple containers in a single pod?
A web application with separate (= in their own containers) logging and monitoring components/adapters is one examples.
A CI/CD pipeline (using Tekton for example) can run multiple containers in one Pod if a Task contains multiple commands.
What are the possible Pod phases?
* Running - The Pod bound to a node and at least one container is running * Failed/Error - At least one container in the Pod terminated with a failure * Succeeded - Every container in the Pod terminated with success * Unknown - Pod's state could not be obtained * Pending - Containers are not yet running (Perhaps images are still being downloaded or the pod wasn't scheduled yet)
True or False? By default, pods are isolated. This means they are unable to receive traffic from any source
False. By default, pods are non-isolated = pods accept traffic from any source.
True or False? The "Pending" phase means the Pod was not yet accepted by the Kubernetes cluster so the scheduler can't run it unless it's accepted
False. "Pending" is after the Pod was accepted by the cluster, but the container can't run for different reasons like images not yet downloaded.
True or False? A single Pod can be split across multiple nodes
False. A single Pod can run on a single node.
You run a pod and you see the status ContainerCreating
True or False? A volume defined in Pod can be accessed by all the containers of that Pod
True.
What happens when you run a Pod with kubectl?
1. Kubectl sends a request to the API server (kube-apiserver) to create the Pod 1. In the the process the user gets authenticated and the request is being validated. 2. etcd is being updated with the data 2. The Scheduler detects that there is an unassigned Pod by monitoring the API server (kube-apiserver) 3. The Scheduler chooses a node to assign the Pod to 1. etcd is being updated with the information 4. The Scheduler updates the API server about which node it chose 5. Kubelet (which also monitors the API server) notices there is a Pod assigned to the same node on which it runs and that Pod isn't running 6. Kubelet sends request to the container engine (e.g. Docker) to create and run the containers 7. An update is sent by Kubelet to the API server (notifying it that the Pod is running) 1. etcd is being updated by the API server again
How to confirm a container is running after running the command kubectl run web --image nginxinc/nginx-unprivileged
* When you run `kubectl describe pods
After running kubectl run database --image mongo you see the status is "CrashLoopBackOff". What could possibly went wrong and what do you do to confirm?
"CrashLoopBackOff" means the Pod is starting, crashing, starting...and so it repeats itself.
There are many different reasons to get this error - lack of permissions, init-container misconfiguration, persistent volume connection issue, etc. One of the ways to check why it happened it to run `kubectl describe po
Explain the purpose of the following lines ``` livenessProbe: exec: command: - cat - /appStatus initialDelaySeconds: 10 periodSeconds: 5 ```
These lines make use of `liveness probe`. It's used to restart a container when it reaches a non-desired state.
In this case, if the command `cat /appStatus` fails, Kubernetes will kill the container and will apply the restart policy. The `initialDelaySeconds: 10` means that Kubelet will wait 10 seconds before running the command/probe for the first time. From that point on, it will run it every 5 seconds, as defined with `periodSeconds`
Explain the purpose of the following lines ``` readinessProbe: tcpSocket: port: 2017 initialDelaySeconds: 15 periodSeconds: 20 ```
They define a readiness probe where the Pod will not be marked as "Ready" before it will be possible to connect to port 2017 of the container. The first check/probe will start after 15 seconds from the moment the container started to run and will continue to run the check/probe every 20 seconds until it will manage to connect to the defined port.
What does the "ErrImagePull" status of a Pod means?
It wasn't able to pull the image specified for running the container(s). This can happen if the client didn't authenticated for example.
More details can be obtained with `kubectl describe po
What happens when you delete a Pod?
1. The `TERM` signal is sent to kill the main processes inside the containers of the given Pod 2. Each container is given a period of 30 seconds to shut down the processes gracefully 3. If the grace period expires, the `KILL` signal is used to kill the processes forcefully and the containers as well
Explain liveness probes
Liveness probes is a useful mechanism used for restarting the container when a certain check/probe, the user has defined, fails.
For example, the user can define that the command `cat /app/status` will run every X seconds and the moment this command fails, the container will be restarted. You can read more about it in [kubernetes.io](https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes)
Explain readiness probes
readiness probes used by Kubelet to know when a container is ready to start running, accepting traffic.
For example, a readiness probe can be to connect port 8080 on a container. Once Kubelet manages to connect it, the Pod is marked as ready You can read more about it in [kubernetes.io](https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes)
How readiness probe status affect Services when they are combined?
Only containers whose state set to Success will be able to receive requests sent to the Service.
Why it's common to have only one container per Pod in most cases?
One reason is that it makes it harder to scale when you need to scale only one of the containers in a given Pod.
True or False? Once a Pod is assisgned to a worker node, it will only run on that node, even if it fails at some point and spins up a new Pod
True.
True or False? Each Pod, when created, gets its own public IP address
False. Each Pod gets an IP address but an internal one and not publicly accessible. To make a Pod externally accessible, we need to use an object called Service in Kubernetes.
What are Static Pods?
[Kubernetes.io](https://kubernetes.io/docs/tasks/configure-pod-container/static-pod/): "Static Pods are managed directly by the kubelet daemon on a specific node, without the API server observing them. Unlike Pods that are managed by the control plane (for example, a Deployment); instead, the kubelet watches each static Pod (and restarts it if it fails)."
True or False? The same as there are "Static Pods" there are other static resources like "deployments" and "replicasets"
False.
What are some use cases for using Static Pods?
One clear use case is running Control Plane Pods - running Pods such as kube-apiserver, scheduler, etc. These should run and operate regardless of whether some components of the cluster work or not and they should run on specific nodes of the cluster.
How to identify which Pods are Static Pods?
The suffix of the Pods is the same as the name of the nodes on which they are running TODO: check if it's always the case.
Which of the following is not a static pod?: * kube-scheduler * kube-proxy * kube-apiserver
kube-proxy - it's a DaemonSet (since it has to be presented on every node in the cluster). There is no one specific node on which it has to run.
Where static Pods manifests are located?
Most of the time it's in /etc/kubernetes/manifests but you can verify with `grep -i static /var/lib/kubelet/config.yaml` to locate the value of `statisPodsPath`. It might be that your config is in different path. To verify run `ps -ef | grep kubelet` and see what is the value of --config argument of the process `/usr/bin/kubelet` The key itself for defining the path of static Pods is `staticPodPath`. So if your config is in `/var/lib/kubelet/config.yaml` you can run `grep staticPodPath /var/lib/kubelet/config.yaml`.
Describe how would you delete a static Pod
Locate the static Pods directory (look at `staticPodPath` in kubelet configuration file). Go to that directory and remove the manifest/definition of the staic Pod (`rm
How to check to which worker node the pods were scheduled to? In other words, how to check on which node a certain Pod is running?
`kubectl get pods -o wide`
How to delete a pod?
`kubectl delete pod pod_name`
List all the pods with the label "env=prod"
`k get po -l env=prod` To count them: `k get po -l env=prod --no-headers | wc -l`
How to list the pods in the current namespace?
`kubectl get po`
How view all the pods running in all the namespaces?
`kubectl get pods --all-namespaces`
You try to run a Pod but it's in "Pending" state. What might be the reason?
One possible reason is that the scheduler which supposed to schedule Pods on nodes, is not running. To verify it, you can run `kubectl get po -A | grep scheduler` or check directly in `kube-system` namespace.
What kubectl logs [pod-name] command does?
Prints the logs for a container in a pod.
What kubectl describe pod [pod name] does? command does?
Show details of a specific resource or group of resources.
Create a static pod with the image python that runs the command sleep 2017
First change to the directory tracked by kubelet for creating static pod: `cd /etc/kubernetes/manifests` (you can verify path by reading kubelet conf file) Now create the definition/manifest in that directory `k run some-pod --image=python --command sleep 2017 --restart=Never --dry-run=client -o yaml > statuc-pod.yaml`
Explain Labels
[Kubernetes.io](https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/): "Labels are key/value pairs that are attached to objects, such as pods. Labels are intended to be used to specify identifying attributes of objects that are meaningful and relevant to users, but do not directly imply semantics to the core system. Labels can be used to organize and to select subsets of objects. Labels can be attached to objects at creation time and subsequently added and modified at any time. Each object can have a set of key/value labels defined. Each Key must be unique for a given object."
Explain selectors
[Kubernetes.io](https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/#label-selectors): "Unlike names and UIDs, labels do not provide uniqueness. In general, we expect many objects to carry the same label(s). Via a label selector, the client/user can identify a set of objects. The label selector is the core grouping primitive in Kubernetes. The API currently supports two types of selectors: equality-based and set-based. A label selector can be made of multiple requirements which are comma-separated. In the case of multiple requirements, all must be satisfied so the comma separator acts as a logical AND (&&) operator."
Provide some actual examples of how labels are used
* Can be used by the scheduler to place certain Pods (with certain labels) on specific nodes * Used by replicasets to track pods which have to be scaled
What are Annotations?
[Kubernetes.io](https://kubernetes.io/docs/concepts/overview/working-with-objects/annotations/): "You can use Kubernetes annotations to attach arbitrary non-identifying metadata to objects. Clients such as tools and libraries can retrieve this metadata."
How annotations different from labels?
[Kuberenets.io](Labels can be used to select objects and to find collections of objects that satisfy certain conditions. In contrast, annotations are not used to identify and select objects. The metadata in an annotation can be small or large, structured or unstructured, and can include characters not permitted by labels.): "Labels can be used to select objects and to find collections of objects that satisfy certain conditions. In contrast, annotations are not used to identify and select objects. The metadata in an annotation can be small or large, structured or unstructured, and can include characters not permitted by labels."
How to view the logs of a container running in a Pod?
`k logs POD_NAME`
There are two containers inside a Pod called "some-pod". What will happen if you run kubectl logs some-pod
It won't work because there are two containers inside the Pod and you need to specify one of them with `kubectl logs POD_NAME -c CONTAINER_NAME`
What is a "Deployment" in Kubernetes?
A Kubernetes Deployment is used to tell Kubernetes how to create or modify instances of the pods that hold a containerized application. Deployments can scale the number of replica pods, enable rollout of updated code in a controlled manner, or roll back to an earlier deployment version if necessary. A Deployment is a declarative statement for the desired state for Pods and Replica Sets.
How to create a deployment with the image "nginx:alpine"?</code>
`kubectl create deployment my-first-deployment --image=nginx:alpine` OR ``` cat << EOF | kubectl create -f - apiVersion: apps/v1 kind: Deployment metadata: name: nginx spec: replicas: 1 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:alpine ```
How to verify a deployment was created?</code>
`kubectl get deployments` or `kubectl get deploy` This command lists all the Deployment objects created and exist in the cluster. It doesn't mean the deployments are readt and running. This can be checked with the "READY" and "AVAILABLE" columns.
How to edit a deployment?</code>
`kubectl edit deployment
What happens after you edit a deployment and change the image?
The pod will terminate and another, new pod, will be created. Also, when looking at the replicaset, you'll see the old replica doesn't have any pods and a new replicaset is created.
How to delete a deployment?
One way is by specifying the deployment name: `kubectl delete deployment [deployment_name]` Another way is using the deployment configuration file: `kubectl delete -f deployment.yaml`
What happens when you delete a deployment?
The pod related to the deployment will terminate and the replicaset will be removed.
What happens behind the scenes when you create a Deployment object?
The following occurs when you run `kubectl create deployment some_deployment --image=nginx` 1. HTTP request sent to kubernetes API server on the cluster to create a new deployment 2. A new Pod object is created and scheduled to one of the workers nodes 3. Kublet on the worker node notices the new Pod and instructs the Container runtime engine to pull the image from the registry 4. A new container is created using the image that was just pulled
How make an app accessible on private or external network?
Using a Service.
Can you use a Deployment for stateful applications?
Fix the following deployment manifest ```yaml apiVersion: apps/v1 kind: Deploy metadata: creationTimestamp: null labels: app: dep name: dep spec: replicas: 3 selector: matchLabels: app: dep strategy: {} template: metadata: creationTimestamp: null labels: app: dep spec: containers: - image: redis name: redis resources: {} status: {} ```
Change `kind: Deploy` to `kind: Deployment`
Fix the following deployment manifest ```yaml apiVersion: apps/v1 kind: Deployment metadata: creationTimestamp: null labels: app: dep name: dep spec: replicas: 3 selector: matchLabels: app: depdep strategy: {} template: metadata: creationTimestamp: null labels: app: dep spec: containers: - image: redis name: redis resources: {} status: {} ```
The selector doesn't match the label (dep vs depdep). To solve it, fix depdep so it's dep instead.
Create a file definition/manifest of a deployment called "dep", with 3 replicas that uses the image 'redis'
`k create deploy dep -o yaml --image=redis --dry-run=client --replicas 3 > deployment.yaml `
Delete the deployment `depdep`
`k delete deploy depdep`
Create a deployment called "pluck" using the image "redis" and make sure it runs 5 replicas
`kubectl create deployment pluck --image=redis` `kubectl scale deployment pluck --replicas=5`
Create a deployment with the following properties: * called "blufer" * using the image "python" * runs 3 replicas * all pods will be placed on a node that has the label "blufer"
`kubectl create deployment blufer --image=python --replicas=3 -o yaml --dry-run=client > deployment.yaml` Add the following section (`vi deployment.yaml`): ``` spec: affinity: nodeAffinity: requiredDuringSchedlingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: blufer operator: Exists ``` `kubectl apply -f deployment.yaml`
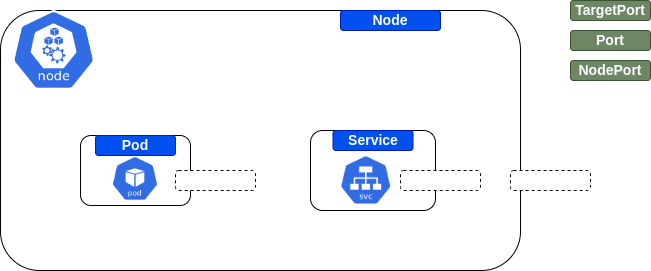
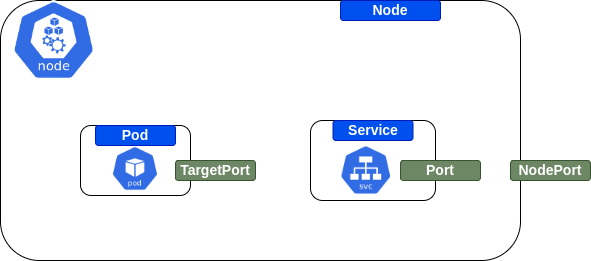
What is a Service in Kubernetes?
"An abstract way to expose an application running on a set of Pods as a network service." - read more [here](https://kubernetes.io/docs/concepts/services-networking/service) In simpler words, it allows you to add an internal or external connectivity to a certain application running in a container.
Place the components in the right placeholders in regards to Kubernetes service
How to create a service for an existing deployment called "alle" on port 8080 so the Pod(s) accessible via a Load Balancer?
The imperative way: `kubectl expose deployment alle --type=LoadBalancer --port 8080`
True or False? The lifecycle of Pods and Services isn't connected so when a Pod dies, the Service still stays
True
After creating a service, how to check it was created?
`kubectl get svc`
What's the default Service type?
ClusterIP - used for internal communication.
What Service types are there?
* ClusterIP * NodePort * LoadBalancer * ExternalName More on this topic [here](https://kubernetes.io/docs/concepts/services-networking/service/#publishing-services-service-types)
How Service and Deployment are connected?
The truth is they aren't connected. Service points to Pod(s) directly, without connecting to the Deployment in any way.
What are important steps in defining/adding a Service?
1. Making sure that targetPort of the Service is matching the containerPort of the Pod 2. Making sure that selector matches at least one of the Pod's labels
What is the default service type in Kubernetes and what is it used for?
The default is ClusterIP and it's used for exposing a port internally. It's useful when you want to enable internal communication between Pods and prevent any external access.
How to get information on a certain service?
`kubctl describe service
What the following command does? ``` kubectl expose rs some-replicaset --name=replicaset-svc --target-port=2017 --type=NodePort ```
It exposes a ReplicaSet by creating a service called 'replicaset-svc'. The exposed port is 2017 (this is the port used by the application) and the service type is NodePort which means it will be reachable externally.
True or False? the target port, in the case of running the following command, will be exposed only on one of the Kubernetes cluster nodes but it will routed to all the pods ``` kubectl expose rs some-replicaset --name=replicaset-svc --target-port=2017 --type=NodePort ```
False. It will be exposed on every node of the cluster and will be routed to one of the Pods (which belong to the ReplicaSet)
How to verify that a certain service configured to forward the requests to a given pod
Run `kubectl describe service` and see if the IPs from "Endpoints" match any IPs from the output of `kubectl get pod -o wide`
Explain what will happen when running apply on the following block ``` apiVersion: v1 kind: Service metadata: name: some-app spec: type: NodePort ports: - port: 8080 nodePort: 2017 protocol: TCP selector: type: backend service: some-app ```
It creates a new Service of the type "NodePort" which means it can be used for internal and external communication with the app.
The port of the application is 8080 and the requests will forwarded to this port. The exposed port is 2017. As a note, this is not a common practice, to specify the nodePort.
The port used TCP (instead of UDP) and this is also the default so you don't have to specify it.
The selector used by the Service to know to which Pods to forward the requests. In this case, Pods with the label "type: backend" and "service: some-app".
How to turn the following service into an external one? ``` spec: selector: app: some-app ports: - protocol: TCP port: 8081 targetPort: 8081 ```
Adding `type: LoadBalancer` and `nodePort` ``` spec: selector: app: some-app type: LoadBalancer ports: - protocol: TCP port: 8081 targetPort: 8081 nodePort: 32412 ```
What would you use to route traffic from outside the Kubernetes cluster to services within a cluster?
Ingress
True or False? When "NodePort" is used, "ClusterIP" will be created automatically?
True
When would you use the "LoadBalancer" type
Mostly when you would like to combine it with cloud provider's load balancer
How would you map a service to an external address?
Using the 'ExternalName' directive.
Describe in detail what happens when you create a service
1. Kubectl sends a request to the API server to create a Service 2. The controller detects there is a new Service 3. Endpoint objects created with the same name as the service, by the controller 4. The controller is using the Service selector to identify the endpoints 5. kube-proxy detects there is a new endpoint object + new service and adds iptables rules to capture traffic to the Service port and redirect it to endpoints 6. kube-dns detects there is a new Service and adds the container record to the dns server
How to list the endpoints of a certain app?
`kubectl get ep
How can you find out information on a Service related to a certain Pod if all you can use is kubectl exec -- </code></summary>
You can run `kubectl exec -- env` which will give you a couple environment variables related to the Service.
Variables such as `[SERVICE_NAME]_SERVICE_HOST`, `[SERVICE_NAME]_SERVICE_PORT`, ...
</b></details>
Describe what happens when a container tries to connect with its corresponding Service for the first time. Explain who added each of the components you include in your description
- The container looks at the nameserver defined in /etc/resolv.conf
- The container queries the nameserver so the address is resolved to the Service IP
- Requests sent to the Service IP are forwarded with iptables rules (or other chosen software) to the endpoint(s).
Explanation as to who added them:
- The nameserver in the container is added by kubelet during the scheduling of the Pod, by using kube-dns
- The DNS record of the service is added by kube-dns during the Service creation
- iptables rules are added by kube-proxy during Endpoint and Service creation
Describe in high level what happens when you run kubctl expose deployment remo --type=LoadBalancer --port 8080
1. Kubectl sends a request to Kubernetes API to create a Service object
2. Kubernetes asks the cloud provider (e.g. AWS, GCP, Azure) to provision a load balancer
3. The newly created load balancer forwards incoming traffic to relevant worker node(s) which forwards the traffic to the relevant containers
After creating a service that forwards incoming external traffic to the containerized application, how to make sure it works?
You can run `curl :` to examine the output.
</b></details>
An internal load balancer in Kubernetes is called ____ and an external load balancer is called ____
An internal load balancer in Kubernetes is called Service and an external load balancer is Ingress
### Ingress
What is Ingress?
From Kubernetes docs: "Ingress exposes HTTP and HTTPS routes from outside the cluster to services within the cluster. Traffic routing is controlled by rules defined on the Ingress resource."
Read more [here](https://kubernetes.io/docs/concepts/services-networking/ingress/)
Complete the following configuration file to make it Ingress
```
metadata:
name: someapp-ingress
spec:
```
There are several ways to answer this question.
```
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: someapp-ingress
spec:
rules:
- host: my.host
http:
paths:
- backend:
serviceName: someapp-internal-service
servicePort: 8080
```
Explain the meaning of "http", "host" and "backend" directives
```
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: someapp-ingress
spec:
rules:
- host: my.host
http:
paths:
- backend:
serviceName: someapp-internal-service
servicePort: 8080
```
host is the entry point of the cluster so basically a valid domain address that maps to cluster's node IP address
the http line used for specifying that incoming requests will be forwarded to the internal service using http.
backend is referencing the internal service (serviceName is the name under metadata and servicePort is the port under the ports section).
Why using a wildcard in ingress host may lead to issues?
The reason you should not wildcard value in a host (like `- host: *`) is because you basically tell your Kubernetes cluster to forward all the traffic to the container where you used this ingress. This may cause the entire cluster to go down.
What is Ingress Controller?
An implementation for Ingress. It's basically another pod (or set of pods) that does evaluates and processes Ingress rules and this it manages all the redirections.
There are multiple Ingress Controller implementations (the one from Kubernetes is Kubernetes Nginx Ingress Controller).
What are some use cases for using Ingress?
* Multiple sub-domains (multiple host entries, each with its own service)
* One domain with multiple services (multiple paths where each one is mapped to a different service/application)
How to list Ingress in your namespace?
kubectl get ingress
What is Ingress Default Backend?
It specifies what do with an incoming request to the Kubernetes cluster that isn't mapped to any backend (= no rule to for mapping the request to a service). If the default backend service isn't defined, it's recommended to define so users still see some kind of message instead of nothing or unclear error.
How to configure a default backend?
Create Service resource that specifies the name of the default backend as reflected in `kubectl describe ingress ...` and the port under the ports section.
How to configure TLS with Ingress?
Add tls and secretName entries.
```
spec:
tls:
- hosts:
- some_app.com
secretName: someapp-secret-tls
```
True or False? When configuring Ingress with TLS, the Secret component must be in the same namespace as the Ingress component
True
Which Kubernetes concept would you use to control traffic flow at the IP address or port level?
Network Policies
How to scale an application (deplyoment) so it runs more than one instance of the application?
To run two instances of the applicaation?
`kubectl scale deployment --replicas=2`
You can specify any other number, given that your application knows how to scale.
</b></details>
### ReplicaSets
What is the purpose of ReplicaSet?
[kubernetes.io](https://kubernetes.io/docs/concepts/workloads/controllers/replicaset): "A ReplicaSet's purpose is to maintain a stable set of replica Pods running at any given time. As such, it is often used to guarantee the availability of a specified number of identical Pods."
In simpler words, a ReplicaSet will ensure the specified number of Pods replicas is running for a selected Pod. If there are more Pods than defined in the ReplicaSet, some will be removed. If there are less than what is defined in the ReplicaSet then, then more replicas will be added.
What the following block of lines does?
```
spec:
replicas: 2
selector:
matchLabels:
type: backend
template:
metadata:
labels:
type: backend
spec:
containers:
- name: httpd-yup
image: httpd
```
It defines a replicaset for Pods whose type is set to "backend" so at any given point of time there will be 2 concurrent Pods running.
What will happen when a Pod, created by ReplicaSet, is deleted directly with kubectl delete po ...?
The ReplicaSet will create a new Pod in order to reach the desired number of replicas.
True or False? If a ReplicaSet defines 2 replicas but there 3 Pods running matching the ReplicaSet selector, it will do nothing
False. It will terminate one of the Pods to reach the desired state of 2 replicas.
Describe the sequence of events in case of creating a ReplicaSet
* The client (e.g. kubectl) sends a request to the API server to create a ReplicaSet
* The Controller detects there is a new event requesting for a ReplicaSet
* The controller creates new Pod definitions (the exact number depends on what is defined in the ReplicaSet definition)
* The scheduler detects unassigned Pods and decides to which nodes to assign the Pods. This information sent to the API server
* Kubelet detects that two Pods were assigned to the node it's running on (as it constantly watching the API server)
* Kubelet sends requests to the container engine, to create the containers that are part of the Pod
* Kubelet sends a request to the API server to notify it the Pods were created
How to list ReplicaSets in the current namespace?
`kubectl get rs`
Is it possible to delete ReplicaSet without deleting the Pods it created?
Yes, with `--cascase=false`.
`kubectl delete -f rs.yaml --cascade=false`
What is the default number of replicas if not explicitly specified?
1
What the following output of kubectl get rs means?
NAME DESIRED CURRENT READY AGE
web 2 2 0 2m23s
The replicaset `web` has 2 replicas. It seems that the containers inside the Pod(s) are not yet running since the value of READY is 0. It might be normal since it takes time for some containers to start running and it might be due to an error. Running `kubectl describe po POD_NAME` or `kubectl logs POD_NAME` can give us more information.
True or False? Pods specified by the selector field of ReplicaSet must be created by the ReplicaSet itself
False. The Pods can be already running and initially they can be created by any object. It doesn't matter for the ReplicaSet and not a requirement for it to acquire and monitor them.
True or False? In case of a ReplicaSet, if Pods specified in the selector field don't exists, the ReplicaSet will wait for them to run before doing anything
False. It will take care of running the missing Pods.
In case of a ReplicaSet, Which field is mandatory in the spec section?
The field `template` in spec section is mandatory. It's used by the ReplicaSet to create new Pods when needed.
You've created a ReplicaSet, how to check whether the ReplicaSet found matching Pods or it created new Pods?
`kubectl describe rs `
It will be visible under `Events` (the very last lines)
</b></details>
True or False? Deleting a ReplicaSet will delete the Pods it created
True (and not only the Pods but anything else it created).
True or False? Removing the label from a Pod that is tracked by a ReplicaSet, will cause the ReplicaSet to create a new Pod
True. When the label, used by a ReplicaSet in the selector field, removed from a Pod, that Pod no longer controlled by the ReplicaSet and the ReplicaSet will create a new Pod to compensate for the one it "lost".
How to scale a deployment to 8 replicas?</code>
kubectl scale deploy --replicas=8
</b></details>
ReplicaSets are running the moment the user executed the command to create them (like kubectl create -f rs.yaml)
False. It can take some time, depends on what exactly you are running. To see if they are up and running, run `kubectl get rs` and watch the 'READY' column.
How to expose a ReplicaSet as a new service?
`kubectl expose rs --name= --target-port= --type=NodePort`
Few notes:
- the target port depends on which port the app is using in the container
- type can be different and doesn't has to be specifically "NodePort"
</b></details>
Fix the following ReplicaSet definition
```yaml
apiVersion: apps/v1
kind: ReplicaCet
metadata:
name: redis
labels:
app: redis
tier: cache
spec:
selector:
matchLabels:
tier: cache
template:
metadata:
labels:
tier: cachy
spec:
containers:
- name: redis
image: redis
```
kind should be ReplicaSet and not ReplicaCet :)
Fix the following ReplicaSet definition
```yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: redis
labels:
app: redis
tier: cache
spec:
selector:
matchLabels:
tier: cache
template:
metadata:
labels:
tier: cachy
spec:
containers:
- name: redis
image: redis
```
The selector doesn't match the label (cache vs cachy). To solve it, fix cachy so it's cache instead.
How to check which container image was used as part of replica set called "repli"?
`k describe rs repli | grep -i image`
How to check how many Pods are ready as part of a replica set called "repli"?
`k describe rs repli | grep -i "Pods Status"`
How to delete a replica set called "rori"?
`k delete rs rori`
How to modify a replica set called "rori" to use a different image?
`k edis rs rori`
Scale up a replica set called "rori" to run 5 Pods instead of 2
`k scale rs rori --replicas=5`
Scale down a replica set called "rori" to run 1 Pod instead of 5
`k scale rs rori --replicas=1`
### DaemonSet
What's a DaemonSet?
[Kubernetes.io](https://kubernetes.io/docs/concepts/workloads/controllers/daemonset): "A DaemonSet ensures that all (or some) Nodes run a copy of a Pod. As nodes are added to the cluster, Pods are added to them. As nodes are removed from the cluster, those Pods are garbage collected. Deleting a DaemonSet will clean up the Pods it created."
What's the difference between a ReplicaSet and DaemonSet?
A ReplicaSet's purpose is to maintain a stable set of replica Pods running at any given time.
A DaemonSet ensures that all Nodes run a copy of a Pod.
What are some use cases for using a DaemonSet?
* Monitoring: You would like to perform monitoring on every node part of cluster. For example datadog pod runs on every node using a daemonset
* Logging: You would like to having logging set up on every node part of your cluster
* Networking: there is networking component you need on every node for all nodes to communicate between them
How DaemonSet works?
Historically, up 1.12, it was done with NodeName attribute.
Starting 1.12, it's achieved with regular scheduler and node affinity.
#### DaemonSet - Commands
How to list all daemonsets in the current namespace?
`kubectl get ds`
### StatefulSet
Explain StatefulSet
StatefulSet is the workload API object used to manage stateful applications. Manages the deployment and scaling of a set of Pods, and provides guarantees about the ordering and uniqueness of these Pods.[Learn more](https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/)
### Storage
#### Volumes
What is a volume in regards to Kubernetes?
A directory accessible by the containers inside a certain Pod and containers. The mechanism responsible for creating the directory, managing it, ... mainly depends on the volume type.
What volume types are you familiar with?
* emptyDir: created when a Pod assigned to a node and ceases to exist when the Pod is no longer running on that node
* hostPath: mounts a path from the host itself. Usually not used due to security risks but has multiple use-cases where it's needed like access to some internal host paths (`/sys`, `/var/lib`, etc.)
Which problems, volumes in Kubernetes solve?
1. Sharing files between containers running in the same Pod
2. Storage in containers is ephemeral - it usually doesn't last for long. For example, when a container crashes, you lose all on-disk data. Certain volumes allows to manage such situation by persistent volumes
Explain ephemeral volume types vs. persistent volumes in regards to Pods
Ephemeral volume types have the lifetime of a pod as opposed to persistent volumes which exist beyond the lifetime of a Pod.
Provide at least one use-case for each of the following volume types:
* emptyDir
* hostPath
* EmptyDir: You need a temporary data that you can afford to lose if the Pod is deleted. For example short-lived data required for one-time operations.
* hostPath: You need access to paths on the host itself (like data from `/sys` or data generated in `/var/lib`)
### Networking
True or False? By default there is no communication between two Pods in two different namespaces
False. By default two Pods in two different namespaces are able to communicate with each other.
Try it for yourself:
kubectl run test-prod -n prod --image ubuntu -- sleep 2000000000
kubectl run test-dev -n dev --image ubuntu -- sleep 2000000000
`k describe po test-prod -n prod` to get the IP of test-prod Pod.
Access dev Pod: `kubectl exec --stdin --tty test-dev -n dev -- /bin/bash`
And ping the IP of test-prod Pod you get earlier.You'll see that there is communication between the two pods, in two separate namespaces.
### Network Policies
Explain Network Policies
[kubernetes.io](https://kubernetes.io/docs/concepts/services-networking/network-policies): "NetworkPolicies are an application-centric construct which allow you to specify how a pod is allowed to communicate with various network "entities"..."
In simpler words, Network Policies specify how pods are allowed/disallowed to communicate with each other and/or other network endpoints.
What are some use cases for using Network Policies?
- Security: You want to prevent from everyone to communicate with a certain pod for security reasons
- Controlling network traffic: You would like to deny network flow between two specific nodes
True or False? If no network policies are applied to a pod, then no connections to or from it are allowed
False. By default pods are non-isolated.
In case of two pods, if there is an egress policy on the source denining traffic and ingress policy on the destination that allows traffic then, traffic will be allowed or denied?
Denied. Both source and destination policies has to allow traffic for it to be allowed.
Where Kubernetes cluster stores the cluster state?
etcd
### etcd
What is etcd?
etcd is an open source distributed key-value store used to hold and manage the critical information that distributed systems need to keep running.
[Read more here](https://www.redhat.com/en/topics/containers/what-is-etcd)
True or False? Etcd holds the current status of any kubernetes component
True
True or False? The API server is the only component which communicates directly with etcd
True
True or False? application data is not stored in etcd
True
Why etcd? Why not some SQL or NoSQL database?
When chosen as the data store etcd was (and still is of course):
* Highly Available - you can deploy multiple nodes
* Fully Replicated - any node in etcd cluster is "primary" node and has full access to the data
* Consistent - reads return latest data
* Secured - supports both TLS and SSL
* Speed - high performance data store (10k writes per sec!)
### Namespaces
What are namespaces?
Namespaces allow you split your cluster into virtual clusters where you can group your applications in a way that makes sense and is completely separated from the other groups (so you can for example create an app with the same name in two different namespaces)
Why to use namespaces? What is the problem with using one default namespace?
When using the default namespace alone, it becomes hard over time to get an overview of all the applications you manage in your cluster. Namespaces make it easier to organize the applications into groups that makes sense, like a namespace of all the monitoring applications and a namespace for all the security applications, etc.
Namespaces can also be useful for managing Blue/Green environments where each namespace can include a different version of an app and also share resources that are in other namespaces (namespaces like logging, monitoring, etc.).
Another use case for namespaces is one cluster, multiple teams. When multiple teams use the same cluster, they might end up stepping on each others toes. For example if they end up creating an app with the same name it means one of the teams overridden the app of the other team because there can't be too apps in Kubernetes with the same name (in the same namespace).
True or False? When a namespace is deleted all resources in that namespace are not deleted but moved to another default namespace
False. When a namespace is deleted, the resources in that namespace are deleted as well.
What special namespaces are there by default when creating a Kubernetes cluster?
* default
* kube-system
* kube-public
* kube-node-lease
What can you find in kube-system namespace?
* Master and Kubectl processes
* System processes
While namespaces do provide scope for resources, they are not isolating them
True. Try create two pods in two separate namespaces for example, and you'll see there is a connection between the two.
#### Namespaces - commands
How to list all namespaces?</code>
`kubectl get namespaces` OR `kubectl get ns`
Create a namespace called 'alle'
`k create ns alle`
Check how many namespaces are there
`k get ns --no-headers | wc -l`
Check how many pods exist in the "dev" namespace
`k get po -n dev`
Create a pod called "kartos" in the namespace dev. The pod should be using the "redis" image.
If the namespace doesn't exist already: `k create ns dev`
`k run kratos --image=redis -n dev`
You are looking for a Pod called "atreus". How to check in which namespace it runs?
`k get po -A | grep atreus`
What kube-public contains?
* A configmap, which contains cluster information
* Publicly accessible data
How to get the name of the current namespace?</code>
`kubectl config view | grep namespace`
What kube-node-lease contains?
It holds information on heartbeats of nodes. Each node gets an object which holds information about its availability.
True or False? With namespaces you can limit the resources consumed by the users/teams
True. With namespaces you can limit CPU, RAM and storage usage.
How to switch to another namespace? In other words how to change active namespace?</code>
`kubectl config set-context --current --namespace=some-namespace` and validate with `kubectl config view --minify | grep namespace:`
OR
`kubens some-namespace`
#### Resources Quota
What is Resource Quota?</code>
Resource quota provides constraints that limit aggregate resource consumption per namespace. It can limit the quantity of objects that can be created in a namespace by type, as well as the total amount of compute resources that may be consumed by resources in that namespace.
How to create a Resource Quota?</code>
kubectl create quota some-quota --hard-cpu=2,pods=2
Which resources are accessible from different namespaces?</code>
Services.
Which service and in which namespace the following file is referencing?
```
apiVersion: v1
kind: ConfigMap
metadata:
name: some-configmap
data:
some_url: samurai.jack
```
It's referencing the service "samurai" in the namespace called "jack".
Which components can't be created within a namespace?</code>
Volume and Node.
How to list all the components that bound to a namespace?</code>
`kubectl api-resources --namespaced=true`
How to create components in a namespace?</code>
One way is by specifying --namespace like this: `kubectl apply -f my_component.yaml --namespace=some-namespace`
Another way is by specifying it in the YAML itself:
```
apiVersion: v1
kind: ConfigMap
metadata:
name: some-configmap
namespace: some-namespace
```
and you can verify with: `kubectl get configmap -n some-namespace`
How to execute the command "ls" in an existing pod?</code>
kubectl exec some-pod -it -- ls
How to create a service that exposes a deployment?</code>
kubectl expose deploy some-deployment --port=80 --target-port=8080
How to create a pod and a service with one command?</code>
kubectl run nginx --image=nginx --restart=Never --port 80 --expose
Describe in detail what the following command does kubectl create deployment kubernetes-httpd --image=httpd
Why to create kind deployment, if pods can be launched with replicaset?
How to get list of resources which are not bound to a specific namespace?</code>
kubectl api-resources --namespaced=false
How to delete all pods whose status is not "Running"?</code>
kubectl delete pods --field-selector=status.phase!='Running'
How to display the resources usages of pods?
kubectl top pod
Perhaps a general question but, you suspect one of the pods is having issues, you don't know what exactly. What do you do?
Start by inspecting the pods status. we can use the command `kubectl get pods` (--all-namespaces for pods in system namespace)
If we see "Error" status, we can keep debugging by running the command `kubectl describe pod [name]`. In case we still don't see anything useful we can try stern for log tailing.
In case we find out there was a temporary issue with the pod or the system, we can try restarting the pod with the following `kubectl scale deployment [name] --replicas=0`
Setting the replicas to 0 will shut down the process. Now start it with `kubectl scale deployment [name] --replicas=1`
What happens what pods are using too much memory? (more than its limit)
They become candidates to for termination.
Describe how roll-back works
True or False? Memory is a compressible resource, meaning that when a container reach the memory limit, it will keep running
False. CPU is a compressible resource while memory is a non compressible resource - once a container reached the memory limit, it will be terminated.
### Operators
What is an Operator?
Explained [here](https://kubernetes.io/docs/concepts/extend-kubernetes/operator)
"Operators are software extensions to Kubernetes that make use of custom resources to manage applications and their components. Operators follow Kubernetes principles, notably the control loop."
In simpler words, you can think about an operator as a custom control loop in Kubernetes.
Why do we need Operators?
The process of managing stateful applications in Kubernetes isn't as straightforward as managing stateless applications where reaching the desired status and upgrades are both handled the same way for every replica. In stateful applications, upgrading each replica might require different handling due to the stateful nature of the app, each replica might be in a different status. As a result, we often need a human operator to manage stateful applications. Kubernetes Operator is suppose to assist with this.
This also help with automating a standard process on multiple Kubernetes clusters
What components the Operator consists of?
1. CRD (Custom Resource Definition) - You are fanmiliar with Kubernetes resources like Deployment, Pod, Service, etc. CRD is also a resource, but one that you or the developer the operator defines.
2. Controller - Custom control loop which runs against the CRD
Explain CRD
CRD is Custom Resource Definitions. It's custom Kubernetes component which extends K8s API.
TODO(abregman): add more info.
How Operator works?
It uses the control loop used by Kubernetes in general. It watches for changes in the application state. The difference is that is uses a custom control loop.
In addition, it also makes use of CRD's (Custom Resources Definitions) so basically it extends Kubernetes API.
True or False? Kubernetes Operator used for stateful applications
True
Explain what is the OLM (Operator Lifecycle Manager) and what is it used for
What is the Operator Framework?
open source toolkit used to manage k8s native applications, called operators, in an automated and efficient way.
What components the Operator Framework consists of?
1. Operator SDK - allows developers to build operators
2. Operator Lifecycle Manager - helps to install, update and generally manage the lifecycle of all operators
3. Operator Metering - Enables usage reporting for operators that provide specialized services
4.
Describe in detail what is the Operator Lifecycle Manager
It's part of the Operator Framework, used for managing the lifecycle of operators. It basically extends Kubernetes so a user can use a declarative way to manage operators (installation, upgrade, ...).
What openshift-operator-lifecycle-manager namespace includes?
It includes:
* catalog-operator - Resolving and installing ClusterServiceVersions the resource they specify.
* olm-operator - Deploys applications defined by ClusterServiceVersion resource
What is kubconfig? What do you use it for?
A kubeconfig file is a file used to configure access to Kubernetes when used in conjunction with the kubectl commandline tool (or other clients).
Use kubeconfig files to organize information about clusters, users, namespaces, and authentication mechanisms.
Would you use Helm, Go or something else for creating an Operator?
Depends on the scope and maturity of the Operator. If it mainly covers installation and upgrades, Helm might be enough. If you want to go for Lifecycle management, insights and auto-pilot, this is where you'd probably use Go.
Are there any tools, projects you are using for building Operators?
This one is based more on a personal experience and taste...
* Operator Framework
* Kubebuilder
* Controller Runtime
...
### Secrets
Explain Kubernetes Secrets
Secrets let you store and manage sensitive information (passwords, ssh keys, etc.)
How to create a Secret from a key and value?
`kubectl create secret generic some-secret --from-literal=password='donttellmypassword'`
How to create a Secret from a file?
`kubectl create secret generic some-secret --from-file=/some/file.txt`
What type: Opaque in a secret file means? What other types are there?
Opaque is the default type used for key-value pairs.
True or False? storing data in a Secret component makes it automatically secured
False. Some known security mechanisms like "encryption" aren't enabled by default.
What is the problem with the following Secret file:
```
apiVersion: v1
kind: Secret
metadata:
name: some-secret
type: Opaque
data:
password: mySecretPassword
```
Password isn't encrypted.
You should run something like this: `echo -n 'mySecretPassword' | base64` and paste the result to the file instead of using plain-text.
What the following in a Deployment configuration file means?
```
spec:
containers:
- name: USER_PASSWORD
valueFrom:
secretKeyRef:
name: some-secret
key: password
```
USER_PASSWORD environment variable will store the value from password key in the secret called "some-secret"
In other words, you reference a value from a Kubernetes Secret.
How to commit secrets to Git and in general how to use encrypted secrets?
One possible process would be as follows:
1. You create a Kubernetes secret (but don't commit it)
2. You encrypt it using some 3rd party project (.e.g kubeseal)
3. You apply the seald/encrypted secret
4. You commit the the sealed secret to Git
5. You deploy an application that requires the secret and it can be automatically decrypted by using for example a Bitnami Sealed secrets controller
### Volumes
True or False? Kubernetes provides data persistence out of the box, so when you restart a pod, data is saved
False
Explain "Persistent Volumes". Why do we need it?
Persistent Volumes allow us to save data so basically they provide storage that doesn't depend on the pod lifecycle.
True or False? Persistent Volume must be available to all nodes because the pod can restart on any of them
True
What types of persistent volumes are there?
* NFS
* iSCSI
* CephFS
* ...
What is PersistentVolumeClaim?
Explain Volume Snapshots
Volume snapshots let you create a copy of your volume at a specific point in time.
True or False? Kubernetes manages data persistence
False
Explain Storage Classes
Explain "Dynamic Provisioning" and "Static Provisioning"
The main difference relies on the moment when you want to configure storage. For instance, if you need to pre-populate data in a volume, you choose static provisioning. Whereas, if you need to create volumes on demand, you go for dynamic provisioning.
Explain Access Modes
What is CSI Volume Cloning?
Explain "Ephemeral Volumes"
What types of ephemeral volumes Kubernetes supports?
What is Reclaim Policy?
What reclaim policies are there?
* Retain
* Recycle
* Delete
### Access Control
What is RBAC?
RBAC in Kubernetes is the mechanism that enables you to configure fine-grained and specific sets of permissions that define how a given user, or group of users, can interact with any Kubernetes object in cluster, or in a specific Namespace of cluster.
Explain the Role and RoleBinding" objects
What is the difference between Role and ClusterRole objects?
The difference between them is that a Role is used at a namespace level whereas a ClusterRole is for the entire cluster.
Explain what are "Service Accounts" and in which scenario would use create/use one
[Kubernetes.io](https://kubernetes.io/docs/tasks/configure-pod-container/configure-service-account): "A service account provides an identity for processes that run in a Pod."
An example of when to use one:
You define a pipeline that needs to build and push an image. In order to have sufficient permissions to build an push an image, that pipeline would require a service account with sufficient permissions.
What happens you create a pod and you DON'T specify a service account?
The pod is automatically assigned with the default service account (in the namespace where the pod is running).
Explain how Service Accounts are different from User Accounts
- User accounts are global while Service accounts unique per namespace
- User accounts are meant for humans or client processes while Service accounts are for processes which run in pods
How to list Service Accounts?
`kubectl get serviceaccounts`
Explain "Security Context"
[kubernetes.io](https://kubernetes.io/docs/tasks/configure-pod-container/security-context): "A security context defines privilege and access control settings for a Pod or Container."
### Patterns
### CronJob
Explain what is CronJob and what is it used for
A CronJob creates Jobs on a repeating schedule. One CronJob object is like one line of a crontab (cron table) file. It runs a job periodically on a given schedule, written in Cron format.
What possible issue can arise from using the following spec and how to fix it?
```
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: some-cron-job
spec:
schedule: '*/1 * * * *'
startingDeadlineSeconds: 10
concurrencyPolicy: Allow
```
If the cron job fails, the next job will not replace the previous one due to the "concurrencyPolicy" value which is "Allow". It will keep spawning new jobs and so eventually the system will be filled with failed cron jobs.
To avoid such problem, the "concurrencyPolicy" value should be either "Replace" or "Forbid".
What issue might arise from using the following CronJob and how to fix it?
```
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: "some-cron-job"
spec:
schedule: '*/1 * * * *'
jobTemplate:
spec:
template:
spec:
restartPolicy: Never
concurrencyPolicy: Forbid
successfulJobsHistoryLimit: 1
failedJobsHistoryLimit: 1
```
The following lines placed under the template:
```
concurrencyPolicy: Forbid
successfulJobsHistoryLimit: 1
failedJobsHistoryLimit: 1
```
As a result this configuration isn't part of the cron job spec hence the cron job has no limits which can cause issues like OOM and potentially lead to API server being down.
To fix it, these lines should placed in the spec of the cron job, above or under the "schedule" directive in the above example.
### Misc
Explain Imperative Management vs. Declarative Management
Explain what Kubernetes Service Discovery means
You have one Kubernetes cluster and multiple teams that would like to use it. You would like to limit the resources each team consumes in the cluster. Which Kubernetes concept would you use for that?
Namespaces will allow to limit resources and also make sure there are no collisions between teams when working in the cluster (like creating an app with the same name).
What Kube Proxy does?
Kube Proxy is a network proxy that runs on each node in your cluster, implementing part of the Kubernetes Service concept
What "Resources Quotas" are used for and how?
Explain ConfigMap
Separate configuration from pods.
It's good for cases where you might need to change configuration at some point but you don't want to restart the application or rebuild the image so you create a ConfigMap and connect it to a pod but externally to the pod.
Overall it's good for:
* Sharing the same configuration between different pods
* Storing external to the pod configuration
How to use ConfigMaps?
1. Create it (from key&value, a file or an env file)
2. Attach it. Mount a configmap as a volume
True or False? Sensitive data, like credentials, should be stored in a ConfigMap
False. Use secret.
Explain "Horizontal Pod Autoscaler"
In Kubernetes, a HorizontalPodAutoscaler automatically updates a workload resource with the aim of automatically scaling the workload to match demand.
When you delete a pod, is it deleted instantly? (a moment after running the command)
What does being cloud-native mean?
The term cloud native refers to the concept of building and running applications to take advantage of the distributed computing offered by the cloud delivery model.
Explain the pet and cattle approach of infrastructure with respect to kubernetes
Describe how you one proceeds to run a containerized web app in K8s, which should be reachable from a public URL.
How would you troubleshoot your cluster if some applications are not reachable any more?
Describe what CustomResourceDefinitions there are in the Kubernetes world? What they can be used for?
How does scheduling work in kubernetes?
The control plane component kube-scheduler asks the following questions,
1. What to schedule? It tries to understand the pod-definition specifications
2. Which node to schedule? It tries to determine the best node with available resources to spin a pod
3. Binds the Pod to a given node
View more [here](https://www.youtube.com/watch?v=rDCWxkvPlAw)
How are labels and selectors used?
What QoS classes are there?
* Guaranteed
* Burstable
* BestEffort
Explain Labels. What are they and why would one use them?
Kubernetes labels are key-value pairs that can connect identifying metadata with Kubernetes objects.
Explain Selectors
What is Kubeconfig?
### Gatekeeper
What is Gatekeeper?
[Gatekeeper docs](https://open-policy-agent.github.io/gatekeeper/website/docs): "Gatekeeper is a validating (mutating TBA) webhook that enforces CRD-based policies executed by Open Policy Agent"
Explain how Gatekeeper works
On every request sent to the Kubernetes cluster, Gatekeeper sends the policies and the resources to OPA (Open Policy Agent) to check if it violates any policy. If it does, Gatekeeper will return the policy error message back. If it isn't violates any policy, the request will reach the cluster.
### Policy Testing
What is Conftest?
Conftest allows you to write tests against structured files. You can think of it as tests library for Kubernetes resources.
It is mostly used in testing environments such as CI pipelines or local hooks.
What is Datree? How is it different from Conftest?
Same as Conftest, it is used for policy testing and enforcement. The difference is that it comes with built-in policies.
### Helm
What is Helm?
Package manager for Kubernetes. Basically the ability to package YAML files and distribute them to other users and apply them in the cluster(s).
As a concept it's quite common and can be found in many platforms and services. Think for example on package managers in operating systems. If you use Fedora/RHEL that would be dnf. If you use Ubuntu then, apt. If you don't use Linux, then a different question should be asked and it's why? but that's another topic :)
Why do we need Helm? What would be the use case for using it?
Sometimes when you would like to deploy a certain application to your cluster, you need to create multiple YAML files/components like: Secret, Service, ConfigMap, etc. This can be tedious task. So it would make sense to ease the process by introducing something that will allow us to share these bundle of YAMLs every time we would like to add an application to our cluster. This something is called Helm.
A common scenario is having multiple Kubernetes clusters (prod, dev, staging). Instead of individually applying different YAMLs in each cluster, it makes more sense to create one Chart and install it in every cluster.
Another scenario is, you would like to share what you've created with the community. For people and companies to easily deploy your application in their cluster.
Explain "Helm Charts"
Helm Charts is a bundle of YAML files. A bundle that you can consume from repositories or create your own and publish it to the repositories.
It is said that Helm is also Templating Engine. What does it mean?
It is useful for scenarios where you have multiple applications and all are similar, so there are minor differences in their configuration files and most values are the same. With Helm you can define a common blueprint for all of them and the values that are not fixed and change can be placeholders. This is called a template file and it looks similar to the following
```
apiVersion: v1
kind: Pod
metadata:
name: {[ .Values.name ]}
spec:
containers:
- name: {{ .Values.container.name }}
image: {{ .Values.container.image }}
port: {{ .Values.container.port }}
```
The values themselves will in separate file:
```
name: some-app
container:
name: some-app-container
image: some-app-image
port: 1991
```
What are some use cases for using Helm template file?
* Deploy the same application across multiple different environments
* CI/CD
Explain the Helm Chart Directory Structure
someChart/ -> the name of the chart
Chart.yaml -> meta information on the chart
values.yaml -> values for template files
charts/ -> chart dependencies
templates/ -> templates files :)
How Helm supports release management?
Helm allows you to upgrade, remove and rollback to previous versions of charts. In version 2 of Helm it was with what is known as "Tiller". In version 3, it was removed due to security concerns.
#### Commands
How do you search for charts?
`helm search hub [some_keyword]`
Is it possible to override values in values.yaml file when installing a chart?
Yes. You can pass another values file:
`helm install --values=override-values.yaml [CHART_NAME]`
Or directly on the command line: `helm install --set some_key=some_value`
How do you list deployed releases?
`helm ls` or `helm list`
How to execute a rollback?
`helm rollback RELEASE_NAME REVISION_ID`
How to view revision history for a certain release?
`helm history RELEASE_NAME`
How to upgrade a release?
`helm upgrade RELEASE_NAME CHART_NAME`
### Security
What security best practices do you follow in regards to the Kubernetes cluster?
* Secure inter-service communication (one way is to use Istio to provide mutual TLS)
* Isolate different resources into separate namespaces based on some logical groups
* Use supported container runtime (if you use Docker then drop it because it's deprecated. You might want to CRI-O as an engine and podman for CLI)
* Test properly changes to the cluster (e.g. consider using Datree to prevent kubernetes misconfigurations)
* Limit who can do what (by using for example OPA gatekeeper) in the cluster
* Use NetworkPolicy to apply network security
* Consider using tools (e.g. Falco) for monitoring threats
### Troubleshooting Scenarios
Running kubectl get pods you see Pods in "Pending" status. What would you do?
One possible path is to run `kubectl describe pod ` to get more details.
You might see one of the following:
* Cluster is full. In this case, extend the cluster.
* ResourcesQuota limits are met. In this case you might want to modify them
* Check if PersistentVolumeClaim mount is pending
If none of the above helped, run the command (`get pods`) with `-o wide` to see if the node is assigned to a node. If not, there might be an issue with scheduler.
</b></details>
Users unable to reach an application running on a Pod on Kubernetes. What might be the issue and how to check?
One possible path is to start with checking the Pod status.
1. Is the Pod pending? if yes, check for the reason with `kubectl describe pod `
TODO: finish this...
</b></details>
### Istio
What is Istio? What is it used for?
Istio is an open source service mesh that helps organizations run distributed, microservices-based apps anywhere. Istio enables organizations to secure, connect, and monitor microservices, so they can modernize their enterprise apps more swiftly and securely.
### Controllers
What are controllers?
[Kubernetes.io](https://kubernetes.io/docs/concepts/architecture/controller): "In Kubernetes, controllers are control loops that watch the state of your cluster, then make or request changes where needed. Each controller tries to move the current cluster state closer to the desired state."
Name two controllers you are familiar with
1. Node Controller: manages the nodes of a cluster. Among other things, the controller is responsible for monitoring nodes' health - if the node is suddenly unreachable it will evacuate all the pods running on it and will mark the node status accordingly.
2. Replication Controller - monitors the status of pod replicas based on what should be running. It makes sure the number of pods that should be running is actually running
What process is responsible for running and installing the different controllers?
Kube-Controller-Manager
What is the control loop? How it works?
Explained [here](https://www.youtube.com/watch?v=i9V4oCa5f9I)
What are all the phases/steps of a control loop?
- Observe - identify the cluster current state
- Diff - Identify whether a diff exists between current state and desired state
- Act - Bring current cluster state to the desired state (basically reach a state where there is no diff)
### Scheduler
True of False? The scheduler is responsible for both deciding where a Pod will run and actually running it
False. While the scheduler is responsible for choosing the node on which the Pod will run, Kubelet is the one that actually runs the Pod.
How to schedule a pod on a node called "node1"?
`k run some-pod --image=redix -o yaml --dry-run=client > pod.yaml`
`vi pod.yaml` and add:
```
spec:
nodeName: node1
```
`k apply -f pod.yaml`
Note: if you don't have a node1 in your cluster the Pod will be stuck on "Pending" state.
#### Node Affinity
Using node affinity, set a Pod to schedule on a node where the key is "region" and value is either "asia" or "emea"
`vi pod.yaml`
```yaml
affinity:
nodeAffinity:
requiredDuringSchedlingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: region
operator: In
values:
- asia
- emea
```
Using node affinity, set a Pod to never schedule on a node where the key is "region" and value is "neverland"
`vi pod.yaml`
```yaml
affinity:
nodeAffinity:
requiredDuringSchedlingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: region
operator: NotIn
values:
- neverland
```
True of False? Using the node affinity type "requiredDuringSchedlingIgnoredDuringExecution" means the scheduler can't schedule unless the rule is met
True
True of False? Using the node affinity type "preferredDuringSchedlingIgnoredDuringExecution" means the scheduler can't schedule unless the rule is met
False. The scheduler tries to find a node that meets the requirements/rules and if it doesn't it will schedule the Pod anyway.
Can you deploy multiple schedulers?
Yes, it is possible. You can run another pod with a command similar to:
```
spec:
containers:
- command:
- kube-scheduler
- --address=127.0.0.1
- --leader-elect=true
- --scheduler-name=some-custom-scheduler
...
```
Assuming you have multiple schedulers, how to know which scheduler was used for a given Pod?
Running `kubectl get events` you can see which scheduler was used.
You want to run a new Pod and you would like it to be scheduled by a custom scheduler. How to achieve it?
Add the following to the spec of the Pod:
```
spec:
schedulerName: some-custom-scheduler
```
### Taints
Check if there are taints on node "master"
`k describe no master | grep -i taints`
Create a taint on one of the nodes in your cluster with key of "app" and value of "web" and effect of "NoSchedule". Verify it was applied
`k taint node minikube app=web:NoSchedule`
`k describe no minikube | grep -i taints`
You applied a taint with k taint node minikube app=web:NoSchedule on the only node in your cluster and then executed kubectl run some-pod --image=redis. What will happen?
The Pod will remain in "Pending" status due to the only node in the cluster having a taint of "app=web".
You applied a taint with k taint node minikube app=web:NoSchedule on the only node in your cluster and then executed kubectl run some-pod --image=redis but the Pod is in pending state. How to fix it?
`kubectl edit po some-pod` and add the following
```
- effect: NoSchedule
key: app
operator: Equal
value: web
```
Exit and save. The pod should be in Running state now.
Remove an existing taint from one of the nodes in your cluster
`k taint node minikube app=web:NoSchedule-`
What taint effects are there? Explain each one of them
`NoSchedule`: prevents from resources to be scheduled on a certain node
`PreferNoSchedule`: will prefer to shcedule resources on other nodes before resorting to scheduling the resource on the chosen node (on which the taint was applied)
`NoExecute`: Applying "NoSchedule" will not evict already running Pods (or other resources) from the node as opposed to "NoExecute" which will evict any already running resource from the Node
### Resource Limits
Explain why one would specify resource limits in regards to Pods
* You know how much RAM and/or CPU your app should be consuming and anything above that is not valid
* You would like to make sure that everyone can run their apps in the cluster and resources are not being solely used by one type of application
True or False? Resource limits applied on a Pod level meaning, if limits is 2gb RAM and there are two container in a Pod that it's 1gb RAM each
False. It's per container and not per Pod.
#### Resources Limits - Commands
Check if there are any limits on one of the pods in your cluster
`kubectl describe po | grep -i limits`
</b></details>
Run a pod called "yay" with the image "python" and resources request of 64Mi memory and 250m CPU
`kubectl run yay --image=python --dry-run=client -o yaml > pod.yaml`
`vi pod.yaml`
```
spec:
containers:
- image: python
imagePullPolicy: Always
name: yay
resources:
requests:
cpu: 250m
memory: 64Mi
```
`kubectl apply -f pod.yaml`
Run a pod called "yay2" with the image "python". Make sure it has resources request of 64Mi memory and 250m CPU and the limits are 128Mi memory and 500m CPU
`kubectl run yay2 --image=python --dry-run=client -o yaml > pod.yaml`
`vi pod.yaml`
```
spec:
containers:
- image: python
imagePullPolicy: Always
name: yay2
resources:
limits:
cpu: 500m
memory: 128Mi
requests:
cpu: 250m
memory: 64Mi
```
`kubectl apply -f pod.yaml`
### Monitoring
What monitoring solutions are you familiar with in regards to Kubernetes?
There are many types of monitoring solutions for Kubernetes. Some open-source, some are in-memory, some of them cost money, ... here is a short list:
* metrics-server: in-memory open source monitoring
* datadog: $$$
* promethues: open source monitoring solution
Describe how the monitoring solution you are working with monitors Kubernetes and
This very much depends on what you chose to use. Let's address some of the solutions:
* metrics-server: an open source and free monitoring solution that uses the cAdvisor component of kubelet to retrieve information on the cluster and its resources and stores them in-memory.
Once installed, after some time you can run commands like `kubectl top node` and `kubectl top pod` to view performance metrics on nodes, pods and other resources.
TODO: add more monitoring solutions
### Kustomize
What is Kustomize?
Explain the need for Kustomize by describing actual use cases
* You have an helm chart of an application used by multiple teams in your organization and there is a requirement to add annotation to the app specifying the name of the of team owning the app
* Without Kustomize you would need to copy the files (chart template in this case) and modify it to include the specific annotations we need
* With Kustomize you don't need to copy the entire repo or files
* You are asked to apply a change/patch to some app without modifying the original files of the app
* With Kustomize you can define kustomization.yml file that defines these customizations so you don't need to touch the original app files
Describe in high-level how Kustomize works
1. You add kustomization.yml file in the folder of the app you would like to customize.
1. You define the customizations you would like to perform
2. You run `kustomize build APP_PATH` where your kustomization.yml also resides
### Deployment Strategies
What rollout/deployment strategies are you familiar with?
* Blue/Green Deployments: You deploy a new version of your app, while old version still running, and you start redirecting traffic to the new version of the app
* Canary Deployments: You deploy a new version of your app and start redirecting **portion** of your users/traffic to the new version. So you the migration to the new version is much more gradual
Explain Blue/Green deployments/rollouts in detail
Blue/Green deployment steps:
1. Traffic coming from users through a load balancer to the application which is currently version 1
Users -> Load Balancer -> App Version 1
2. A new application version 2 is deployed (while version 1 still running)
Users -> Load Balancer -> App Version 1
App Version 2
3. If version 2 runs properly, traffic switched to it instead of version 1
User -> Load Balancer App version 1
-> App Version 2
4. Whether old version is removed or keep running but without users being redirected to it, is based on team or company decision
Pros:
* We can rollback/switch quickly to previous version at any point
Cons:
* In case of an issue with new version, ALL users are affected (instead of small portion/percentage)
Explain Canary deployments/rollouts in detail
Canary deployment steps:
1. Traffic coming from users through a load balancer to the application which is currently version 1
Users -> Load Balancer -> App Version 1
2. A new application version 2 is deployed (while version 1 still running) and part of the traffic is redirected to the new version
Users -> Load Balancer ->(95% of the traffic) App Version 1
->(5% of the traffic) App Version 2
3. If the new version (2) runs well, more traffic is redirected to it
Users -> Load Balancer ->(70% of the traffic) App Version 1
->(30% of the traffic) App Version 2
3. If everything runs well, at some point all traffic is redirected to the new version
Users -> Load Balancer -> App Version 2
Pros:
* If there is any issue with the new deployed app version, only some portion of the users affected, instead of all of them
Cons:
* Testing of new version is neccesrialy in the production environment (as the user traffic is exists only there)
What ways are you familiar with to implement deployment strategies (like canary, blue/green) in Kubernetes?
There are multiple ways. One of them is Argo Rollouts.
### Scenarios
An engineer form your organization told you he is interested only in seeing his team resources in Kubernetes. Instead, in reality, he sees resources of the whole organization, from multiple different teams. What Kubernetes concept can you use in order to deal with it?
Namespaces. See the following [namespaces question and answer](#namespaces-use-cases) for more information.
An engineer in your team runs a Pod but the status he sees is "CrashLoopBackOff". What does it means? How to identify the issue?
The container failed to run (due to different reasons) and Kubernetes tries to run the Pod again after some delay (= BackOff time).
Some reasons for it to fail:
- Misconfiguration - misspelling, non supported value, etc.
- Resource not available - nodes are down, PV not mounted, etc.
Some ways to debug:
1. `kubectl describe pod POD_NAME`
1. Focus on `State` (which should be Waiting, CrashLoopBackOff) and `Last State` which should tell what happened before (as in why it failed)
2. Run `kubectl logs mypod`
1. This should provide an accurate output of
2. For specific container, you can add `-c CONTAINER_NAME`
An engineer form your organization asked whether there is a way to prevent from Pods (with cretain label) to be scheduled on one of the nodes in the cluster. Your reply is:
Yes, using taints, we could run the following command and it will prevent from all resources with label "app=web" to be scheduled on node1: `kubectl taint node node1 app=web:NoSchedule`
You would like to limit the number of resources being used in your cluster. For example no more than 4 replicasets, 2 services, etc. How would you achieve that?
Using ResourceQuats
You can run `kubectl exec
Variables such as `[SERVICE_NAME]_SERVICE_HOST`, `[SERVICE_NAME]_SERVICE_PORT`, ... </b></details>
Describe what happens when a container tries to connect with its corresponding Service for the first time. Explain who added each of the components you include in your description
- The container looks at the nameserver defined in /etc/resolv.conf - The container queries the nameserver so the address is resolved to the Service IP - Requests sent to the Service IP are forwarded with iptables rules (or other chosen software) to the endpoint(s). Explanation as to who added them: - The nameserver in the container is added by kubelet during the scheduling of the Pod, by using kube-dns - The DNS record of the service is added by kube-dns during the Service creation - iptables rules are added by kube-proxy during Endpoint and Service creation
Describe in high level what happens when you run kubctl expose deployment remo --type=LoadBalancer --port 8080
1. Kubectl sends a request to Kubernetes API to create a Service object 2. Kubernetes asks the cloud provider (e.g. AWS, GCP, Azure) to provision a load balancer 3. The newly created load balancer forwards incoming traffic to relevant worker node(s) which forwards the traffic to the relevant containers
After creating a service that forwards incoming external traffic to the containerized application, how to make sure it works?
You can run `curl
An internal load balancer in Kubernetes is called ____ and an external load balancer is called ____
An internal load balancer in Kubernetes is called Service and an external load balancer is Ingress
What is Ingress?
From Kubernetes docs: "Ingress exposes HTTP and HTTPS routes from outside the cluster to services within the cluster. Traffic routing is controlled by rules defined on the Ingress resource." Read more [here](https://kubernetes.io/docs/concepts/services-networking/ingress/)
Complete the following configuration file to make it Ingress ``` metadata: name: someapp-ingress spec: ```
There are several ways to answer this question. ``` apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: someapp-ingress spec: rules: - host: my.host http: paths: - backend: serviceName: someapp-internal-service servicePort: 8080 ```
Explain the meaning of "http", "host" and "backend" directives ``` apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: someapp-ingress spec: rules: - host: my.host http: paths: - backend: serviceName: someapp-internal-service servicePort: 8080 ```
host is the entry point of the cluster so basically a valid domain address that maps to cluster's node IP address
the http line used for specifying that incoming requests will be forwarded to the internal service using http.
backend is referencing the internal service (serviceName is the name under metadata and servicePort is the port under the ports section).
Why using a wildcard in ingress host may lead to issues?
The reason you should not wildcard value in a host (like `- host: *`) is because you basically tell your Kubernetes cluster to forward all the traffic to the container where you used this ingress. This may cause the entire cluster to go down.
What is Ingress Controller?
An implementation for Ingress. It's basically another pod (or set of pods) that does evaluates and processes Ingress rules and this it manages all the redirections. There are multiple Ingress Controller implementations (the one from Kubernetes is Kubernetes Nginx Ingress Controller).
What are some use cases for using Ingress?
* Multiple sub-domains (multiple host entries, each with its own service) * One domain with multiple services (multiple paths where each one is mapped to a different service/application)
How to list Ingress in your namespace?
kubectl get ingress
What is Ingress Default Backend?
It specifies what do with an incoming request to the Kubernetes cluster that isn't mapped to any backend (= no rule to for mapping the request to a service). If the default backend service isn't defined, it's recommended to define so users still see some kind of message instead of nothing or unclear error.
How to configure a default backend?
Create Service resource that specifies the name of the default backend as reflected in `kubectl describe ingress ...` and the port under the ports section.
How to configure TLS with Ingress?
Add tls and secretName entries. ``` spec: tls: - hosts: - some_app.com secretName: someapp-secret-tls ```
True or False? When configuring Ingress with TLS, the Secret component must be in the same namespace as the Ingress component
True
Which Kubernetes concept would you use to control traffic flow at the IP address or port level?
Network Policies
How to scale an application (deplyoment) so it runs more than one instance of the application?
To run two instances of the applicaation? `kubectl scale deployment
What is the purpose of ReplicaSet?
[kubernetes.io](https://kubernetes.io/docs/concepts/workloads/controllers/replicaset): "A ReplicaSet's purpose is to maintain a stable set of replica Pods running at any given time. As such, it is often used to guarantee the availability of a specified number of identical Pods." In simpler words, a ReplicaSet will ensure the specified number of Pods replicas is running for a selected Pod. If there are more Pods than defined in the ReplicaSet, some will be removed. If there are less than what is defined in the ReplicaSet then, then more replicas will be added.
What the following block of lines does? ``` spec: replicas: 2 selector: matchLabels: type: backend template: metadata: labels: type: backend spec: containers: - name: httpd-yup image: httpd ```
It defines a replicaset for Pods whose type is set to "backend" so at any given point of time there will be 2 concurrent Pods running.
What will happen when a Pod, created by ReplicaSet, is deleted directly with kubectl delete po ...?
The ReplicaSet will create a new Pod in order to reach the desired number of replicas.
True or False? If a ReplicaSet defines 2 replicas but there 3 Pods running matching the ReplicaSet selector, it will do nothing
False. It will terminate one of the Pods to reach the desired state of 2 replicas.
Describe the sequence of events in case of creating a ReplicaSet
* The client (e.g. kubectl) sends a request to the API server to create a ReplicaSet * The Controller detects there is a new event requesting for a ReplicaSet * The controller creates new Pod definitions (the exact number depends on what is defined in the ReplicaSet definition) * The scheduler detects unassigned Pods and decides to which nodes to assign the Pods. This information sent to the API server * Kubelet detects that two Pods were assigned to the node it's running on (as it constantly watching the API server) * Kubelet sends requests to the container engine, to create the containers that are part of the Pod * Kubelet sends a request to the API server to notify it the Pods were created
How to list ReplicaSets in the current namespace?
`kubectl get rs`
Is it possible to delete ReplicaSet without deleting the Pods it created?
Yes, with `--cascase=false`. `kubectl delete -f rs.yaml --cascade=false`
What is the default number of replicas if not explicitly specified?
1
What the following output of kubectl get rs means?
NAME DESIRED CURRENT READY AGE
web 2 2 0 2m23s
The replicaset `web` has 2 replicas. It seems that the containers inside the Pod(s) are not yet running since the value of READY is 0. It might be normal since it takes time for some containers to start running and it might be due to an error. Running `kubectl describe po POD_NAME` or `kubectl logs POD_NAME` can give us more information.
True or False? Pods specified by the selector field of ReplicaSet must be created by the ReplicaSet itself
False. The Pods can be already running and initially they can be created by any object. It doesn't matter for the ReplicaSet and not a requirement for it to acquire and monitor them.
True or False? In case of a ReplicaSet, if Pods specified in the selector field don't exists, the ReplicaSet will wait for them to run before doing anything
False. It will take care of running the missing Pods.
In case of a ReplicaSet, Which field is mandatory in the spec section?
The field `template` in spec section is mandatory. It's used by the ReplicaSet to create new Pods when needed.
You've created a ReplicaSet, how to check whether the ReplicaSet found matching Pods or it created new Pods?
`kubectl describe rs
True or False? Deleting a ReplicaSet will delete the Pods it created
True (and not only the Pods but anything else it created).
True or False? Removing the label from a Pod that is tracked by a ReplicaSet, will cause the ReplicaSet to create a new Pod
True. When the label, used by a ReplicaSet in the selector field, removed from a Pod, that Pod no longer controlled by the ReplicaSet and the ReplicaSet will create a new Pod to compensate for the one it "lost".
How to scale a deployment to 8 replicas?</code>
kubectl scale deploy
ReplicaSets are running the moment the user executed the command to create them (like kubectl create -f rs.yaml)
False. It can take some time, depends on what exactly you are running. To see if they are up and running, run `kubectl get rs` and watch the 'READY' column.
How to expose a ReplicaSet as a new service?
`kubectl expose rs
Fix the following ReplicaSet definition ```yaml apiVersion: apps/v1 kind: ReplicaCet metadata: name: redis labels: app: redis tier: cache spec: selector: matchLabels: tier: cache template: metadata: labels: tier: cachy spec: containers: - name: redis image: redis ```
kind should be ReplicaSet and not ReplicaCet :)
Fix the following ReplicaSet definition ```yaml apiVersion: apps/v1 kind: ReplicaSet metadata: name: redis labels: app: redis tier: cache spec: selector: matchLabels: tier: cache template: metadata: labels: tier: cachy spec: containers: - name: redis image: redis ```
The selector doesn't match the label (cache vs cachy). To solve it, fix cachy so it's cache instead.
How to check which container image was used as part of replica set called "repli"?
`k describe rs repli | grep -i image`
How to check how many Pods are ready as part of a replica set called "repli"?
`k describe rs repli | grep -i "Pods Status"`
How to delete a replica set called "rori"?
`k delete rs rori`
How to modify a replica set called "rori" to use a different image?
`k edis rs rori`
Scale up a replica set called "rori" to run 5 Pods instead of 2
`k scale rs rori --replicas=5`
Scale down a replica set called "rori" to run 1 Pod instead of 5
`k scale rs rori --replicas=1`
What's a DaemonSet?
[Kubernetes.io](https://kubernetes.io/docs/concepts/workloads/controllers/daemonset): "A DaemonSet ensures that all (or some) Nodes run a copy of a Pod. As nodes are added to the cluster, Pods are added to them. As nodes are removed from the cluster, those Pods are garbage collected. Deleting a DaemonSet will clean up the Pods it created."
What's the difference between a ReplicaSet and DaemonSet?
A ReplicaSet's purpose is to maintain a stable set of replica Pods running at any given time. A DaemonSet ensures that all Nodes run a copy of a Pod.
What are some use cases for using a DaemonSet?
* Monitoring: You would like to perform monitoring on every node part of cluster. For example datadog pod runs on every node using a daemonset * Logging: You would like to having logging set up on every node part of your cluster * Networking: there is networking component you need on every node for all nodes to communicate between them
How DaemonSet works?
Historically, up 1.12, it was done with NodeName attribute. Starting 1.12, it's achieved with regular scheduler and node affinity.
How to list all daemonsets in the current namespace?
`kubectl get ds`
Explain StatefulSet
StatefulSet is the workload API object used to manage stateful applications. Manages the deployment and scaling of a set of Pods, and provides guarantees about the ordering and uniqueness of these Pods.[Learn more](https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/)
What is a volume in regards to Kubernetes?
A directory accessible by the containers inside a certain Pod and containers. The mechanism responsible for creating the directory, managing it, ... mainly depends on the volume type.
What volume types are you familiar with?
* emptyDir: created when a Pod assigned to a node and ceases to exist when the Pod is no longer running on that node * hostPath: mounts a path from the host itself. Usually not used due to security risks but has multiple use-cases where it's needed like access to some internal host paths (`/sys`, `/var/lib`, etc.)
Which problems, volumes in Kubernetes solve?
1. Sharing files between containers running in the same Pod 2. Storage in containers is ephemeral - it usually doesn't last for long. For example, when a container crashes, you lose all on-disk data. Certain volumes allows to manage such situation by persistent volumes
Explain ephemeral volume types vs. persistent volumes in regards to Pods
Ephemeral volume types have the lifetime of a pod as opposed to persistent volumes which exist beyond the lifetime of a Pod.
Provide at least one use-case for each of the following volume types: * emptyDir * hostPath
* EmptyDir: You need a temporary data that you can afford to lose if the Pod is deleted. For example short-lived data required for one-time operations. * hostPath: You need access to paths on the host itself (like data from `/sys` or data generated in `/var/lib`)
True or False? By default there is no communication between two Pods in two different namespaces
False. By default two Pods in two different namespaces are able to communicate with each other. Try it for yourself: kubectl run test-prod -n prod --image ubuntu -- sleep 2000000000 kubectl run test-dev -n dev --image ubuntu -- sleep 2000000000 `k describe po test-prod -n prod` to get the IP of test-prod Pod. Access dev Pod: `kubectl exec --stdin --tty test-dev -n dev -- /bin/bash` And ping the IP of test-prod Pod you get earlier.You'll see that there is communication between the two pods, in two separate namespaces.
Explain Network Policies
[kubernetes.io](https://kubernetes.io/docs/concepts/services-networking/network-policies): "NetworkPolicies are an application-centric construct which allow you to specify how a pod is allowed to communicate with various network "entities"..." In simpler words, Network Policies specify how pods are allowed/disallowed to communicate with each other and/or other network endpoints.
What are some use cases for using Network Policies?
- Security: You want to prevent from everyone to communicate with a certain pod for security reasons - Controlling network traffic: You would like to deny network flow between two specific nodes
True or False? If no network policies are applied to a pod, then no connections to or from it are allowed
False. By default pods are non-isolated.
In case of two pods, if there is an egress policy on the source denining traffic and ingress policy on the destination that allows traffic then, traffic will be allowed or denied?
Denied. Both source and destination policies has to allow traffic for it to be allowed.
Where Kubernetes cluster stores the cluster state?
etcd
What is etcd?
etcd is an open source distributed key-value store used to hold and manage the critical information that distributed systems need to keep running. [Read more here](https://www.redhat.com/en/topics/containers/what-is-etcd)
True or False? Etcd holds the current status of any kubernetes component
True
True or False? The API server is the only component which communicates directly with etcd
True
True or False? application data is not stored in etcd
True
Why etcd? Why not some SQL or NoSQL database?
When chosen as the data store etcd was (and still is of course): * Highly Available - you can deploy multiple nodes * Fully Replicated - any node in etcd cluster is "primary" node and has full access to the data * Consistent - reads return latest data * Secured - supports both TLS and SSL * Speed - high performance data store (10k writes per sec!)
What are namespaces?
Namespaces allow you split your cluster into virtual clusters where you can group your applications in a way that makes sense and is completely separated from the other groups (so you can for example create an app with the same name in two different namespaces)
Why to use namespaces? What is the problem with using one default namespace?
When using the default namespace alone, it becomes hard over time to get an overview of all the applications you manage in your cluster. Namespaces make it easier to organize the applications into groups that makes sense, like a namespace of all the monitoring applications and a namespace for all the security applications, etc. Namespaces can also be useful for managing Blue/Green environments where each namespace can include a different version of an app and also share resources that are in other namespaces (namespaces like logging, monitoring, etc.). Another use case for namespaces is one cluster, multiple teams. When multiple teams use the same cluster, they might end up stepping on each others toes. For example if they end up creating an app with the same name it means one of the teams overridden the app of the other team because there can't be too apps in Kubernetes with the same name (in the same namespace).
True or False? When a namespace is deleted all resources in that namespace are not deleted but moved to another default namespace
False. When a namespace is deleted, the resources in that namespace are deleted as well.
What special namespaces are there by default when creating a Kubernetes cluster?
* default * kube-system * kube-public * kube-node-lease
What can you find in kube-system namespace?
* Master and Kubectl processes * System processes
While namespaces do provide scope for resources, they are not isolating them
True. Try create two pods in two separate namespaces for example, and you'll see there is a connection between the two.
How to list all namespaces?</code>
`kubectl get namespaces` OR `kubectl get ns`
Create a namespace called 'alle'
`k create ns alle`
Check how many namespaces are there
`k get ns --no-headers | wc -l`
Check how many pods exist in the "dev" namespace
`k get po -n dev`
Create a pod called "kartos" in the namespace dev. The pod should be using the "redis" image.
If the namespace doesn't exist already: `k create ns dev` `k run kratos --image=redis -n dev`
You are looking for a Pod called "atreus". How to check in which namespace it runs?
`k get po -A | grep atreus`
What kube-public contains?
* A configmap, which contains cluster information * Publicly accessible data
How to get the name of the current namespace?</code>
`kubectl config view | grep namespace`
What kube-node-lease contains?
It holds information on heartbeats of nodes. Each node gets an object which holds information about its availability.
True or False? With namespaces you can limit the resources consumed by the users/teams
True. With namespaces you can limit CPU, RAM and storage usage.
How to switch to another namespace? In other words how to change active namespace?</code>
`kubectl config set-context --current --namespace=some-namespace` and validate with `kubectl config view --minify | grep namespace:` OR `kubens some-namespace`
What is Resource Quota?</code>
Resource quota provides constraints that limit aggregate resource consumption per namespace. It can limit the quantity of objects that can be created in a namespace by type, as well as the total amount of compute resources that may be consumed by resources in that namespace.
How to create a Resource Quota?</code>
kubectl create quota some-quota --hard-cpu=2,pods=2
Which resources are accessible from different namespaces?</code>
Services.
Which service and in which namespace the following file is referencing? ``` apiVersion: v1 kind: ConfigMap metadata: name: some-configmap data: some_url: samurai.jack ```
It's referencing the service "samurai" in the namespace called "jack".
Which components can't be created within a namespace?</code>
Volume and Node.
How to list all the components that bound to a namespace?</code>
`kubectl api-resources --namespaced=true`
How to create components in a namespace?</code>
One way is by specifying --namespace like this: `kubectl apply -f my_component.yaml --namespace=some-namespace` Another way is by specifying it in the YAML itself: ``` apiVersion: v1 kind: ConfigMap metadata: name: some-configmap namespace: some-namespace ``` and you can verify with: `kubectl get configmap -n some-namespace`
How to execute the command "ls" in an existing pod?</code>
kubectl exec some-pod -it -- ls
How to create a service that exposes a deployment?</code>
kubectl expose deploy some-deployment --port=80 --target-port=8080
How to create a pod and a service with one command?</code>
kubectl run nginx --image=nginx --restart=Never --port 80 --expose
Describe in detail what the following command does kubectl create deployment kubernetes-httpd --image=httpd
Why to create kind deployment, if pods can be launched with replicaset?
How to get list of resources which are not bound to a specific namespace?</code>
kubectl api-resources --namespaced=false
How to delete all pods whose status is not "Running"?</code>
kubectl delete pods --field-selector=status.phase!='Running'
How to display the resources usages of pods?
kubectl top pod
Perhaps a general question but, you suspect one of the pods is having issues, you don't know what exactly. What do you do?
Start by inspecting the pods status. we can use the command `kubectl get pods` (--all-namespaces for pods in system namespace)
If we see "Error" status, we can keep debugging by running the command `kubectl describe pod [name]`. In case we still don't see anything useful we can try stern for log tailing.
In case we find out there was a temporary issue with the pod or the system, we can try restarting the pod with the following `kubectl scale deployment [name] --replicas=0`
Setting the replicas to 0 will shut down the process. Now start it with `kubectl scale deployment [name] --replicas=1`
What happens what pods are using too much memory? (more than its limit)
They become candidates to for termination.
Describe how roll-back works
True or False? Memory is a compressible resource, meaning that when a container reach the memory limit, it will keep running
False. CPU is a compressible resource while memory is a non compressible resource - once a container reached the memory limit, it will be terminated.
What is an Operator?
Explained [here](https://kubernetes.io/docs/concepts/extend-kubernetes/operator) "Operators are software extensions to Kubernetes that make use of custom resources to manage applications and their components. Operators follow Kubernetes principles, notably the control loop." In simpler words, you can think about an operator as a custom control loop in Kubernetes.
Why do we need Operators?
The process of managing stateful applications in Kubernetes isn't as straightforward as managing stateless applications where reaching the desired status and upgrades are both handled the same way for every replica. In stateful applications, upgrading each replica might require different handling due to the stateful nature of the app, each replica might be in a different status. As a result, we often need a human operator to manage stateful applications. Kubernetes Operator is suppose to assist with this. This also help with automating a standard process on multiple Kubernetes clusters
What components the Operator consists of?
1. CRD (Custom Resource Definition) - You are fanmiliar with Kubernetes resources like Deployment, Pod, Service, etc. CRD is also a resource, but one that you or the developer the operator defines. 2. Controller - Custom control loop which runs against the CRD
Explain CRD
CRD is Custom Resource Definitions. It's custom Kubernetes component which extends K8s API. TODO(abregman): add more info.
How Operator works?
It uses the control loop used by Kubernetes in general. It watches for changes in the application state. The difference is that is uses a custom control loop. In addition, it also makes use of CRD's (Custom Resources Definitions) so basically it extends Kubernetes API.
True or False? Kubernetes Operator used for stateful applications
True
Explain what is the OLM (Operator Lifecycle Manager) and what is it used for
What is the Operator Framework?
open source toolkit used to manage k8s native applications, called operators, in an automated and efficient way.
What components the Operator Framework consists of?
1. Operator SDK - allows developers to build operators 2. Operator Lifecycle Manager - helps to install, update and generally manage the lifecycle of all operators 3. Operator Metering - Enables usage reporting for operators that provide specialized services 4.
Describe in detail what is the Operator Lifecycle Manager
It's part of the Operator Framework, used for managing the lifecycle of operators. It basically extends Kubernetes so a user can use a declarative way to manage operators (installation, upgrade, ...).
What openshift-operator-lifecycle-manager namespace includes?
It includes: * catalog-operator - Resolving and installing ClusterServiceVersions the resource they specify. * olm-operator - Deploys applications defined by ClusterServiceVersion resource
What is kubconfig? What do you use it for?
A kubeconfig file is a file used to configure access to Kubernetes when used in conjunction with the kubectl commandline tool (or other clients). Use kubeconfig files to organize information about clusters, users, namespaces, and authentication mechanisms.
Would you use Helm, Go or something else for creating an Operator?
Depends on the scope and maturity of the Operator. If it mainly covers installation and upgrades, Helm might be enough. If you want to go for Lifecycle management, insights and auto-pilot, this is where you'd probably use Go.
Are there any tools, projects you are using for building Operators?
This one is based more on a personal experience and taste... * Operator Framework * Kubebuilder * Controller Runtime ...
Explain Kubernetes Secrets
Secrets let you store and manage sensitive information (passwords, ssh keys, etc.)
How to create a Secret from a key and value?
`kubectl create secret generic some-secret --from-literal=password='donttellmypassword'`
How to create a Secret from a file?
`kubectl create secret generic some-secret --from-file=/some/file.txt`
What type: Opaque in a secret file means? What other types are there?
Opaque is the default type used for key-value pairs.
True or False? storing data in a Secret component makes it automatically secured
False. Some known security mechanisms like "encryption" aren't enabled by default.
What is the problem with the following Secret file: ``` apiVersion: v1 kind: Secret metadata: name: some-secret type: Opaque data: password: mySecretPassword ```
Password isn't encrypted. You should run something like this: `echo -n 'mySecretPassword' | base64` and paste the result to the file instead of using plain-text.
What the following in a Deployment configuration file means? ``` spec: containers: - name: USER_PASSWORD valueFrom: secretKeyRef: name: some-secret key: password ```
USER_PASSWORD environment variable will store the value from password key in the secret called "some-secret" In other words, you reference a value from a Kubernetes Secret.
How to commit secrets to Git and in general how to use encrypted secrets?
One possible process would be as follows: 1. You create a Kubernetes secret (but don't commit it) 2. You encrypt it using some 3rd party project (.e.g kubeseal) 3. You apply the seald/encrypted secret 4. You commit the the sealed secret to Git 5. You deploy an application that requires the secret and it can be automatically decrypted by using for example a Bitnami Sealed secrets controller
True or False? Kubernetes provides data persistence out of the box, so when you restart a pod, data is saved
False
Explain "Persistent Volumes". Why do we need it?
Persistent Volumes allow us to save data so basically they provide storage that doesn't depend on the pod lifecycle.
True or False? Persistent Volume must be available to all nodes because the pod can restart on any of them
True
What types of persistent volumes are there?
* NFS * iSCSI * CephFS * ...
What is PersistentVolumeClaim?
Explain Volume Snapshots
Volume snapshots let you create a copy of your volume at a specific point in time.
True or False? Kubernetes manages data persistence
False
Explain Storage Classes
Explain "Dynamic Provisioning" and "Static Provisioning"
The main difference relies on the moment when you want to configure storage. For instance, if you need to pre-populate data in a volume, you choose static provisioning. Whereas, if you need to create volumes on demand, you go for dynamic provisioning.
Explain Access Modes
What is CSI Volume Cloning?
Explain "Ephemeral Volumes"
What types of ephemeral volumes Kubernetes supports?
What is Reclaim Policy?
What reclaim policies are there?
* Retain * Recycle * Delete
What is RBAC?
RBAC in Kubernetes is the mechanism that enables you to configure fine-grained and specific sets of permissions that define how a given user, or group of users, can interact with any Kubernetes object in cluster, or in a specific Namespace of cluster.
Explain the Role and RoleBinding" objects
What is the difference between Role and ClusterRole objects?
The difference between them is that a Role is used at a namespace level whereas a ClusterRole is for the entire cluster.
Explain what are "Service Accounts" and in which scenario would use create/use one
[Kubernetes.io](https://kubernetes.io/docs/tasks/configure-pod-container/configure-service-account): "A service account provides an identity for processes that run in a Pod." An example of when to use one: You define a pipeline that needs to build and push an image. In order to have sufficient permissions to build an push an image, that pipeline would require a service account with sufficient permissions.
What happens you create a pod and you DON'T specify a service account?
The pod is automatically assigned with the default service account (in the namespace where the pod is running).
Explain how Service Accounts are different from User Accounts
- User accounts are global while Service accounts unique per namespace - User accounts are meant for humans or client processes while Service accounts are for processes which run in pods
How to list Service Accounts?
`kubectl get serviceaccounts`
Explain "Security Context"
[kubernetes.io](https://kubernetes.io/docs/tasks/configure-pod-container/security-context): "A security context defines privilege and access control settings for a Pod or Container."
Explain what is CronJob and what is it used for
A CronJob creates Jobs on a repeating schedule. One CronJob object is like one line of a crontab (cron table) file. It runs a job periodically on a given schedule, written in Cron format.
What possible issue can arise from using the following spec and how to fix it? ``` apiVersion: batch/v1beta1 kind: CronJob metadata: name: some-cron-job spec: schedule: '*/1 * * * *' startingDeadlineSeconds: 10 concurrencyPolicy: Allow ```
If the cron job fails, the next job will not replace the previous one due to the "concurrencyPolicy" value which is "Allow". It will keep spawning new jobs and so eventually the system will be filled with failed cron jobs. To avoid such problem, the "concurrencyPolicy" value should be either "Replace" or "Forbid".
What issue might arise from using the following CronJob and how to fix it? ``` apiVersion: batch/v1beta1 kind: CronJob metadata: name: "some-cron-job" spec: schedule: '*/1 * * * *' jobTemplate: spec: template: spec: restartPolicy: Never concurrencyPolicy: Forbid successfulJobsHistoryLimit: 1 failedJobsHistoryLimit: 1 ```
The following lines placed under the template: ``` concurrencyPolicy: Forbid successfulJobsHistoryLimit: 1 failedJobsHistoryLimit: 1 ``` As a result this configuration isn't part of the cron job spec hence the cron job has no limits which can cause issues like OOM and potentially lead to API server being down.
To fix it, these lines should placed in the spec of the cron job, above or under the "schedule" directive in the above example.
Explain Imperative Management vs. Declarative Management
Explain what Kubernetes Service Discovery means
You have one Kubernetes cluster and multiple teams that would like to use it. You would like to limit the resources each team consumes in the cluster. Which Kubernetes concept would you use for that?
Namespaces will allow to limit resources and also make sure there are no collisions between teams when working in the cluster (like creating an app with the same name).
What Kube Proxy does?
Kube Proxy is a network proxy that runs on each node in your cluster, implementing part of the Kubernetes Service concept
What "Resources Quotas" are used for and how?
Explain ConfigMap
Separate configuration from pods. It's good for cases where you might need to change configuration at some point but you don't want to restart the application or rebuild the image so you create a ConfigMap and connect it to a pod but externally to the pod. Overall it's good for: * Sharing the same configuration between different pods * Storing external to the pod configuration
How to use ConfigMaps?
1. Create it (from key&value, a file or an env file) 2. Attach it. Mount a configmap as a volume
True or False? Sensitive data, like credentials, should be stored in a ConfigMap
False. Use secret.
Explain "Horizontal Pod Autoscaler"
In Kubernetes, a HorizontalPodAutoscaler automatically updates a workload resource with the aim of automatically scaling the workload to match demand.
When you delete a pod, is it deleted instantly? (a moment after running the command)
What does being cloud-native mean?
The term cloud native refers to the concept of building and running applications to take advantage of the distributed computing offered by the cloud delivery model.
Explain the pet and cattle approach of infrastructure with respect to kubernetes
Describe how you one proceeds to run a containerized web app in K8s, which should be reachable from a public URL.
How would you troubleshoot your cluster if some applications are not reachable any more?
Describe what CustomResourceDefinitions there are in the Kubernetes world? What they can be used for?
How does scheduling work in kubernetes?
The control plane component kube-scheduler asks the following questions, 1. What to schedule? It tries to understand the pod-definition specifications 2. Which node to schedule? It tries to determine the best node with available resources to spin a pod 3. Binds the Pod to a given node View more [here](https://www.youtube.com/watch?v=rDCWxkvPlAw)
How are labels and selectors used?
What QoS classes are there?
* Guaranteed * Burstable * BestEffort
Explain Labels. What are they and why would one use them?
Kubernetes labels are key-value pairs that can connect identifying metadata with Kubernetes objects.
Explain Selectors
What is Kubeconfig?
What is Gatekeeper?
[Gatekeeper docs](https://open-policy-agent.github.io/gatekeeper/website/docs): "Gatekeeper is a validating (mutating TBA) webhook that enforces CRD-based policies executed by Open Policy Agent"
Explain how Gatekeeper works
On every request sent to the Kubernetes cluster, Gatekeeper sends the policies and the resources to OPA (Open Policy Agent) to check if it violates any policy. If it does, Gatekeeper will return the policy error message back. If it isn't violates any policy, the request will reach the cluster.
What is Conftest?
Conftest allows you to write tests against structured files. You can think of it as tests library for Kubernetes resources.
It is mostly used in testing environments such as CI pipelines or local hooks.
What is Datree? How is it different from Conftest?
Same as Conftest, it is used for policy testing and enforcement. The difference is that it comes with built-in policies.
What is Helm?
Package manager for Kubernetes. Basically the ability to package YAML files and distribute them to other users and apply them in the cluster(s). As a concept it's quite common and can be found in many platforms and services. Think for example on package managers in operating systems. If you use Fedora/RHEL that would be dnf. If you use Ubuntu then, apt. If you don't use Linux, then a different question should be asked and it's why? but that's another topic :)
Why do we need Helm? What would be the use case for using it?
Sometimes when you would like to deploy a certain application to your cluster, you need to create multiple YAML files/components like: Secret, Service, ConfigMap, etc. This can be tedious task. So it would make sense to ease the process by introducing something that will allow us to share these bundle of YAMLs every time we would like to add an application to our cluster. This something is called Helm. A common scenario is having multiple Kubernetes clusters (prod, dev, staging). Instead of individually applying different YAMLs in each cluster, it makes more sense to create one Chart and install it in every cluster. Another scenario is, you would like to share what you've created with the community. For people and companies to easily deploy your application in their cluster.
Explain "Helm Charts"
Helm Charts is a bundle of YAML files. A bundle that you can consume from repositories or create your own and publish it to the repositories.
It is said that Helm is also Templating Engine. What does it mean?
It is useful for scenarios where you have multiple applications and all are similar, so there are minor differences in their configuration files and most values are the same. With Helm you can define a common blueprint for all of them and the values that are not fixed and change can be placeholders. This is called a template file and it looks similar to the following ``` apiVersion: v1 kind: Pod metadata: name: {[ .Values.name ]} spec: containers: - name: {{ .Values.container.name }} image: {{ .Values.container.image }} port: {{ .Values.container.port }} ``` The values themselves will in separate file: ``` name: some-app container: name: some-app-container image: some-app-image port: 1991 ```
What are some use cases for using Helm template file?
* Deploy the same application across multiple different environments * CI/CD
Explain the Helm Chart Directory Structure
someChart/ -> the name of the chart Chart.yaml -> meta information on the chart values.yaml -> values for template files charts/ -> chart dependencies templates/ -> templates files :)
How Helm supports release management?
Helm allows you to upgrade, remove and rollback to previous versions of charts. In version 2 of Helm it was with what is known as "Tiller". In version 3, it was removed due to security concerns.
How do you search for charts?
`helm search hub [some_keyword]`
Is it possible to override values in values.yaml file when installing a chart?
Yes. You can pass another values file: `helm install --values=override-values.yaml [CHART_NAME]` Or directly on the command line: `helm install --set some_key=some_value`
How do you list deployed releases?
`helm ls` or `helm list`
How to execute a rollback?
`helm rollback RELEASE_NAME REVISION_ID`
How to view revision history for a certain release?
`helm history RELEASE_NAME`
How to upgrade a release?
`helm upgrade RELEASE_NAME CHART_NAME`
What security best practices do you follow in regards to the Kubernetes cluster?
* Secure inter-service communication (one way is to use Istio to provide mutual TLS) * Isolate different resources into separate namespaces based on some logical groups * Use supported container runtime (if you use Docker then drop it because it's deprecated. You might want to CRI-O as an engine and podman for CLI) * Test properly changes to the cluster (e.g. consider using Datree to prevent kubernetes misconfigurations) * Limit who can do what (by using for example OPA gatekeeper) in the cluster * Use NetworkPolicy to apply network security * Consider using tools (e.g. Falco) for monitoring threats
Running kubectl get pods you see Pods in "Pending" status. What would you do?
One possible path is to run `kubectl describe pod
You might see one of the following: * Cluster is full. In this case, extend the cluster. * ResourcesQuota limits are met. In this case you might want to modify them * Check if PersistentVolumeClaim mount is pending If none of the above helped, run the command (`get pods`) with `-o wide` to see if the node is assigned to a node. If not, there might be an issue with scheduler. </b></details>
Users unable to reach an application running on a Pod on Kubernetes. What might be the issue and how to check?
One possible path is to start with checking the Pod status. 1. Is the Pod pending? if yes, check for the reason with `kubectl describe pod
What is Istio? What is it used for?
Istio is an open source service mesh that helps organizations run distributed, microservices-based apps anywhere. Istio enables organizations to secure, connect, and monitor microservices, so they can modernize their enterprise apps more swiftly and securely.
What are controllers?
[Kubernetes.io](https://kubernetes.io/docs/concepts/architecture/controller): "In Kubernetes, controllers are control loops that watch the state of your cluster, then make or request changes where needed. Each controller tries to move the current cluster state closer to the desired state."
Name two controllers you are familiar with
1. Node Controller: manages the nodes of a cluster. Among other things, the controller is responsible for monitoring nodes' health - if the node is suddenly unreachable it will evacuate all the pods running on it and will mark the node status accordingly. 2. Replication Controller - monitors the status of pod replicas based on what should be running. It makes sure the number of pods that should be running is actually running
What process is responsible for running and installing the different controllers?
Kube-Controller-Manager
What is the control loop? How it works?
Explained [here](https://www.youtube.com/watch?v=i9V4oCa5f9I)
What are all the phases/steps of a control loop?
- Observe - identify the cluster current state - Diff - Identify whether a diff exists between current state and desired state - Act - Bring current cluster state to the desired state (basically reach a state where there is no diff)
True of False? The scheduler is responsible for both deciding where a Pod will run and actually running it
False. While the scheduler is responsible for choosing the node on which the Pod will run, Kubelet is the one that actually runs the Pod.
How to schedule a pod on a node called "node1"?
`k run some-pod --image=redix -o yaml --dry-run=client > pod.yaml` `vi pod.yaml` and add: ``` spec: nodeName: node1 ``` `k apply -f pod.yaml` Note: if you don't have a node1 in your cluster the Pod will be stuck on "Pending" state.
Using node affinity, set a Pod to schedule on a node where the key is "region" and value is either "asia" or "emea"
`vi pod.yaml` ```yaml affinity: nodeAffinity: requiredDuringSchedlingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: region operator: In values: - asia - emea ```
Using node affinity, set a Pod to never schedule on a node where the key is "region" and value is "neverland"
`vi pod.yaml` ```yaml affinity: nodeAffinity: requiredDuringSchedlingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: region operator: NotIn values: - neverland ```
True of False? Using the node affinity type "requiredDuringSchedlingIgnoredDuringExecution" means the scheduler can't schedule unless the rule is met
True
True of False? Using the node affinity type "preferredDuringSchedlingIgnoredDuringExecution" means the scheduler can't schedule unless the rule is met
False. The scheduler tries to find a node that meets the requirements/rules and if it doesn't it will schedule the Pod anyway.
Can you deploy multiple schedulers?
Yes, it is possible. You can run another pod with a command similar to: ``` spec: containers: - command: - kube-scheduler - --address=127.0.0.1 - --leader-elect=true - --scheduler-name=some-custom-scheduler ... ```
Assuming you have multiple schedulers, how to know which scheduler was used for a given Pod?
Running `kubectl get events` you can see which scheduler was used.
You want to run a new Pod and you would like it to be scheduled by a custom scheduler. How to achieve it?
Add the following to the spec of the Pod: ``` spec: schedulerName: some-custom-scheduler ```
Check if there are taints on node "master"
`k describe no master | grep -i taints`
Create a taint on one of the nodes in your cluster with key of "app" and value of "web" and effect of "NoSchedule". Verify it was applied
`k taint node minikube app=web:NoSchedule` `k describe no minikube | grep -i taints`
You applied a taint with k taint node minikube app=web:NoSchedule on the only node in your cluster and then executed kubectl run some-pod --image=redis. What will happen?
The Pod will remain in "Pending" status due to the only node in the cluster having a taint of "app=web".
You applied a taint with k taint node minikube app=web:NoSchedule on the only node in your cluster and then executed kubectl run some-pod --image=redis but the Pod is in pending state. How to fix it?
`kubectl edit po some-pod` and add the following ``` - effect: NoSchedule key: app operator: Equal value: web ``` Exit and save. The pod should be in Running state now.
Remove an existing taint from one of the nodes in your cluster
`k taint node minikube app=web:NoSchedule-`
What taint effects are there? Explain each one of them
`NoSchedule`: prevents from resources to be scheduled on a certain node `PreferNoSchedule`: will prefer to shcedule resources on other nodes before resorting to scheduling the resource on the chosen node (on which the taint was applied) `NoExecute`: Applying "NoSchedule" will not evict already running Pods (or other resources) from the node as opposed to "NoExecute" which will evict any already running resource from the Node
Explain why one would specify resource limits in regards to Pods
* You know how much RAM and/or CPU your app should be consuming and anything above that is not valid * You would like to make sure that everyone can run their apps in the cluster and resources are not being solely used by one type of application
True or False? Resource limits applied on a Pod level meaning, if limits is 2gb RAM and there are two container in a Pod that it's 1gb RAM each
False. It's per container and not per Pod.
Check if there are any limits on one of the pods in your cluster
`kubectl describe po
Run a pod called "yay" with the image "python" and resources request of 64Mi memory and 250m CPU
`kubectl run yay --image=python --dry-run=client -o yaml > pod.yaml` `vi pod.yaml` ``` spec: containers: - image: python imagePullPolicy: Always name: yay resources: requests: cpu: 250m memory: 64Mi ``` `kubectl apply -f pod.yaml`
Run a pod called "yay2" with the image "python". Make sure it has resources request of 64Mi memory and 250m CPU and the limits are 128Mi memory and 500m CPU
`kubectl run yay2 --image=python --dry-run=client -o yaml > pod.yaml` `vi pod.yaml` ``` spec: containers: - image: python imagePullPolicy: Always name: yay2 resources: limits: cpu: 500m memory: 128Mi requests: cpu: 250m memory: 64Mi ``` `kubectl apply -f pod.yaml`
What monitoring solutions are you familiar with in regards to Kubernetes?
There are many types of monitoring solutions for Kubernetes. Some open-source, some are in-memory, some of them cost money, ... here is a short list: * metrics-server: in-memory open source monitoring * datadog: $$$ * promethues: open source monitoring solution
Describe how the monitoring solution you are working with monitors Kubernetes and
This very much depends on what you chose to use. Let's address some of the solutions: * metrics-server: an open source and free monitoring solution that uses the cAdvisor component of kubelet to retrieve information on the cluster and its resources and stores them in-memory. Once installed, after some time you can run commands like `kubectl top node` and `kubectl top pod` to view performance metrics on nodes, pods and other resources. TODO: add more monitoring solutions
What is Kustomize?
Explain the need for Kustomize by describing actual use cases
* You have an helm chart of an application used by multiple teams in your organization and there is a requirement to add annotation to the app specifying the name of the of team owning the app * Without Kustomize you would need to copy the files (chart template in this case) and modify it to include the specific annotations we need * With Kustomize you don't need to copy the entire repo or files * You are asked to apply a change/patch to some app without modifying the original files of the app * With Kustomize you can define kustomization.yml file that defines these customizations so you don't need to touch the original app files
Describe in high-level how Kustomize works
1. You add kustomization.yml file in the folder of the app you would like to customize. 1. You define the customizations you would like to perform 2. You run `kustomize build APP_PATH` where your kustomization.yml also resides
What rollout/deployment strategies are you familiar with?
* Blue/Green Deployments: You deploy a new version of your app, while old version still running, and you start redirecting traffic to the new version of the app * Canary Deployments: You deploy a new version of your app and start redirecting **portion** of your users/traffic to the new version. So you the migration to the new version is much more gradual
Explain Blue/Green deployments/rollouts in detail
Blue/Green deployment steps: 1. Traffic coming from users through a load balancer to the application which is currently version 1 Users -> Load Balancer -> App Version 1 2. A new application version 2 is deployed (while version 1 still running) Users -> Load Balancer -> App Version 1 App Version 2 3. If version 2 runs properly, traffic switched to it instead of version 1 User -> Load Balancer App version 1 -> App Version 2 4. Whether old version is removed or keep running but without users being redirected to it, is based on team or company decision Pros: * We can rollback/switch quickly to previous version at any point Cons: * In case of an issue with new version, ALL users are affected (instead of small portion/percentage)
Explain Canary deployments/rollouts in detail
Canary deployment steps: 1. Traffic coming from users through a load balancer to the application which is currently version 1 Users -> Load Balancer -> App Version 1 2. A new application version 2 is deployed (while version 1 still running) and part of the traffic is redirected to the new version Users -> Load Balancer ->(95% of the traffic) App Version 1 ->(5% of the traffic) App Version 2 3. If the new version (2) runs well, more traffic is redirected to it Users -> Load Balancer ->(70% of the traffic) App Version 1 ->(30% of the traffic) App Version 2 3. If everything runs well, at some point all traffic is redirected to the new version Users -> Load Balancer -> App Version 2 Pros: * If there is any issue with the new deployed app version, only some portion of the users affected, instead of all of them Cons: * Testing of new version is neccesrialy in the production environment (as the user traffic is exists only there)
What ways are you familiar with to implement deployment strategies (like canary, blue/green) in Kubernetes?
There are multiple ways. One of them is Argo Rollouts.
An engineer form your organization told you he is interested only in seeing his team resources in Kubernetes. Instead, in reality, he sees resources of the whole organization, from multiple different teams. What Kubernetes concept can you use in order to deal with it?
Namespaces. See the following [namespaces question and answer](#namespaces-use-cases) for more information.
An engineer in your team runs a Pod but the status he sees is "CrashLoopBackOff". What does it means? How to identify the issue?
The container failed to run (due to different reasons) and Kubernetes tries to run the Pod again after some delay (= BackOff time). Some reasons for it to fail: - Misconfiguration - misspelling, non supported value, etc. - Resource not available - nodes are down, PV not mounted, etc. Some ways to debug: 1. `kubectl describe pod POD_NAME` 1. Focus on `State` (which should be Waiting, CrashLoopBackOff) and `Last State` which should tell what happened before (as in why it failed) 2. Run `kubectl logs mypod` 1. This should provide an accurate output of 2. For specific container, you can add `-c CONTAINER_NAME`
An engineer form your organization asked whether there is a way to prevent from Pods (with cretain label) to be scheduled on one of the nodes in the cluster. Your reply is:
Yes, using taints, we could run the following command and it will prevent from all resources with label "app=web" to be scheduled on node1: `kubectl taint node node1 app=web:NoSchedule`
You would like to limit the number of resources being used in your cluster. For example no more than 4 replicasets, 2 services, etc. How would you achieve that?
Using ResourceQuats